玩了这么久Java的web开发,也差不多玩腻了,尤其是有了SpringBoot之后,简直是保姆级别的框架,所以对web开发兴趣不大了,所以打算来玩更有意思的Java安全。就从Runtime命令执行,反射和反序列化开始吧,刚好反序列化还是两年前玩过的POP链里的内容,有点亲切。
Runtime类命令执行
有回显在cmd执行命令:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| import java.io.*;
import java.nio.charset.StandardCharsets;
public class ping {
public static void main(String[] args) throws IOException {
Process process = Runtime.getRuntime().exec("ping baidu.com");
InputStream inputStream = process.getInputStream();
InputStreamReader inputStreamReader = new InputStreamReader(inputStream, "GBK");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
String line = null;
while((line = bufferedReader.readLine()) != null){
byte[] bytes = line.getBytes(StandardCharsets.UTF_8);
String utf8Content = new String(bytes, StandardCharsets.UTF_8);
System.out.println(utf8Content);
}
bufferedReader.close();
inputStreamReader.close();
inputStream.close();
}
}
|
因为Windows默认的cmd编码为GBK,所以回显到InputStreamReader类中时,再输出到默认为UTF-8编码的IDEA控制台会乱码,使用上面的操作可以将GBK按字节转为UTF-8。
1
2
| byte[] bytes = line.getBytes(StandardCharsets.UTF_8);
String utf8Content = new String(bytes, StandardCharsets.UTF_8);
|
针对不同操作系统的RCE
Windows下使用cmd(相对powershell限制更少):
1
2
| String [] cmd = {"cmd","/C","calc.exe"};
Process proc = Runtime.getRuntime().exec(cmd);
|
Linux下使用bash:
1
2
| String [] cmd = {"/bin/sh","-c","ls"};
Process proc = Runtime.getRuntime().exec(cmd);
|
使用Java的System类读取系统信息:
1
| System.getProperty("os.name");
|
针对不同操作系统的命令执行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
public class Test {
public static void main(String[] args) throws IOException {
String property = System.getProperty("os.name");
String [] cmd1={"cmd","/C","start calc.exe"};
String [] cmd2={"/bin/sh","-c","ls"};
String [] cmd = null;
System.out.println(property);
if (property.contains("Windows")){
cmd= cmd1;
}
else {
cmd= cmd1;
}
Process process =Runtime.getRuntime().exec(cmd);
InputStream inputStream = process.getInputStream();
InputStreamReader inputStreamReader = new InputStreamReader(inputStream);
BufferedReader inputBufferedReader = new BufferedReader(inputStreamReader);
StringBuilder stringBuilder=new StringBuilder();
String line = null;
while ((line = inputBufferedReader.readLine()) != null) {
stringBuilder.append(line);
System.out.println(line);
}
inputBufferedReader.close();
inputBufferedReader=null;
inputStreamReader.close();
inputStreamReader=null;
inputStream.close();
inputStream=null;
}
}
|
反射
Java的反射机制
核心是在程序运行时动态加载类并获取类的详细信息,从而操作类或对象的属性和方法。本质是JVM得到class对象之后,再通过class对象进行反编译,从而获取对象的各种信息。
Java属于先编译再运行的语言,程序中对象的类型在编译期就确定下来了,而当程序在运行时可能需要动态加载某些类,这些类因为之前用不到,所以没有被加载到JVM。通过反射,可以在运行时动态地创建对象并调用其属性,不需要提前在编译期知道运行的对象是谁。
反射调用方法时可以忽略权限检查,因此可能会破坏封装性而导致安全问题。
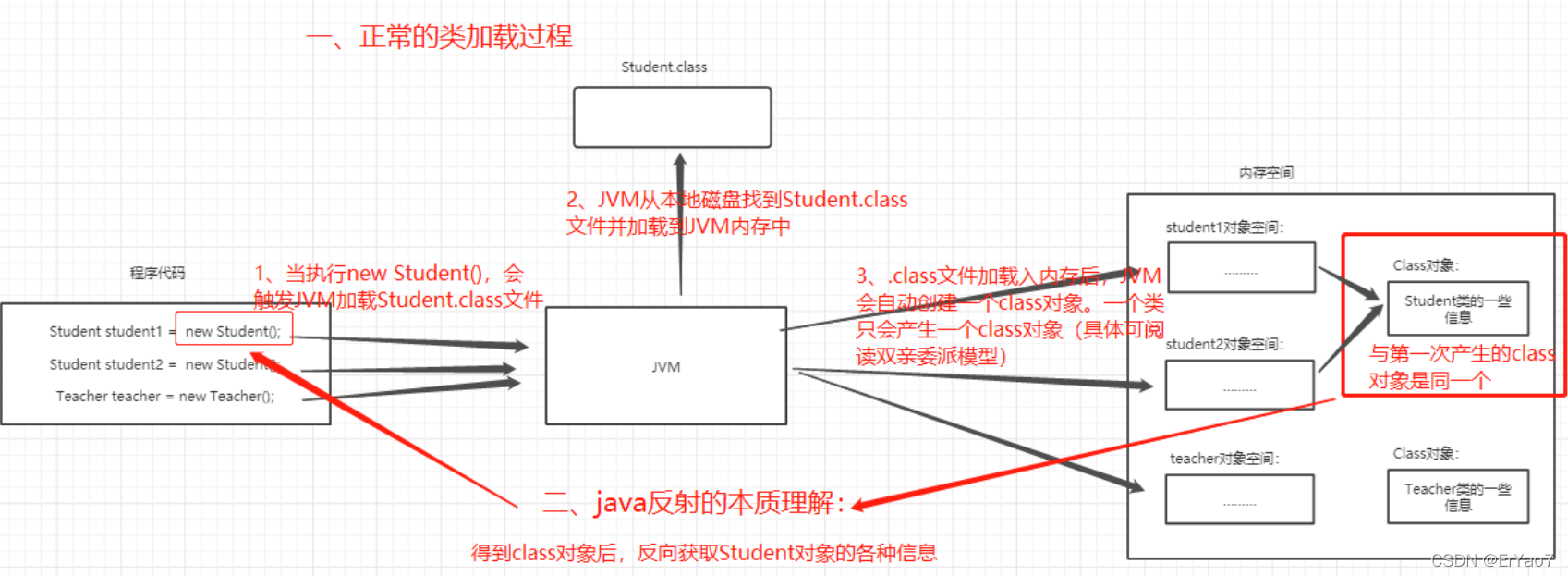
反射的用途
可用于写通用的框架,例如Spring的IOC依赖注入加载bean就用到了反射。
还可用于反编译:.class–>.java,通过反射机制访问java对象的属性,方法,构造方法等
加载数据库驱动JDBC时也用到了反射:
1
2
| Class.forName("com.mysql.jdbc.Driver");
Connection conn = DriverManager.getConnection(url, user, password);
|
基本使用
通过类名获取类——有三种方法
1
2
3
4
| String className = "java.lang.Runtime";
Class runtimeClass1 = Class.forName(className);
Class runtimeClass2 = java.lang.Runtime.class;
Class runtimeClass3 = ClassLoader.getSystemClassLoader().loadClass(className);
|
获取类的构造器
1
2
3
| Constructor constructor = runtimeClass1.getDeclaredConstructor();
constructor.setAccessible(true);
|
获取类的方法
1
2
| Method method = class.getDeclaredMethod("方法名");
Method method = class.getDeclaredMethod("方法名", 参数类型如String.class,多个参数用","号隔开);
|
执行类的方法
1
| Process process = (Process) runtimeMethod.invoke(runtimeInstance, "calc");
|
Invoke方法:
invoke就是调用类中的方法,最简单的用法是可以把方法参数化invoke(class, method)
这里则是使用了 class.invoke(method,”参数”)的一个方式。
还可以把方法名存进数组v[],然后循环里invoke(test,v[i]),就顺序调用了全部方法。
操作类的成员变量
1
2
3
4
5
6
7
8
|
Field fields = class.getDeclaredFields();
Field field = class.getDeclaredField("变量名");
Object obj = field.get(类实例对象);
field.set(类实例对象, 修改后的值);
|
注:反射修改成员变量可无视权限,即private或protected都可以。
应用——可用于绕过对import Runtime类的过滤:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.lang.reflect.Constructor;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
public class RuntimeTest {
public static void main(String[] args) throws ClassNotFoundException, NoSuchMethodException, IllegalAccessException, InvocationTargetException, InstantiationException, IOException {
Class<?> runtimeClass1 = Class.forName("java.lang.Runtime");
Constructor<?> constructor = runtimeClass1.getDeclaredConstructor();
constructor.setAccessible(true);
Object runtimeInstance = constructor.newInstance();
Method method = runtimeClass1.getMethod("exec",String.class);
Process process = (Process) method.invoke(runtimeInstance,"calc");
InputStream inputStream = process.getInputStream();
InputStreamReader inputStreamReader = new InputStreamReader(inputStream);
BufferedReader inputBufferedReader = new BufferedReader(inputStreamReader);
String line = null;
while ((line = inputBufferedReader.readLine()) != null) {
System.out.println(line);
}
inputBufferedReader.close();
inputStreamReader.close();
inputStream.close();
}
}
|
序列化与反序列化
基本概念
序列化和反序列化的概念,把对象转换为字节序列的过程称为对象的序列化。
把字节序列恢复为对象的过程称为对象的反序列化。
对象的序列化主要有两种用途:
1) 把对象的字节序列永久地保存到硬盘上,通常存放在一个文件中;
2) 在网络上传送对象的字节序列。
在很多应用中,需要对某些对象进行序列化,让它们离开内存空间,入住物理硬盘,以便长期保存。比如最常见的是Web服务器中的Session对象,当有 10万用户并发访问,就有可能出现10万个Session对象,内存可能吃不消,于是Web容器就会把一些seesion先序列化到硬盘中,等要用了,再把保存在硬盘中的对象还原到内存中。
当两个进程在进行远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的形式在网络上传送。发送方需要把这个Java对象转换为字节序列,才能在网络上传送;接收方则需要把字节序列再恢复为Java对象。
反序列化应用
序列化:
反序列化:
Java反序列化时会执⾏readObject()⽅法,所以如果readObject()⽅法被恶意构造 的话,就有可能导致命令执⾏。
需要序列号/反序列化的类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| package com.Serializable;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.Serializable;
public class User implements Serializable {
private static final long serialVersionUID = 2632590740470689522L;
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
private void readObject(ObjectInputStream in ) throws IOException, ClassNotFoundException {
in.defaultReadObject();
Runtime.getRuntime().exec("calc.exe");
}
}
|
序列化/反序列化应用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| package com.Serializable;
import java.io.*;
public class Test {
public static void main(String args[]) throws Exception{
User user = new User();
user.setName("testClass");
OutputStream outputStream = new FileOutputStream(new File("E:\\Java-Learn\\src\\main\\java\\com\\Serializable\\test.ser"));
ObjectOutputStream objectOutputStream = new ObjectOutputStream(outputStream);
objectOutputStream.writeObject(user);
InputStream inputStream = new FileInputStream(new File("E:\\Java-Learn\\src\\main\\java\\com\\Serializable\\test.ser"));
ObjectInputStream objectInputStream = new ObjectInputStream(inputStream);
User test = (User) objectInputStream.readObject();
}
}
|
序列号
当我们没有自定义序列化ID
如果我们没有自定义序列化id,当我们修改User 类的时候,编译器又为我们User 类生成了一个UID,而序列化和反序列化就是通过对比其SerialversionUID来进行的,一旦SerialversionUID不匹配,反序列化就无法成功。在实际的生产环境中,如果我们有需求要在序列化后添加一个字段或者方法,应该怎么办?那就是自己去指定serialVersionUID。
设置序列化ID
序列化运行时将一个版本号与每个称为SerialVersionUID的可序列化类相关联,在反序列化过程中使用该序列号验证序列化对象的发送方和接收方是否为该对象加载了与序列化兼容的类。如果接收方为对象加载的类的UID与相应发送方类的UID不同,则反序列化将导致InvalidClassException. 可序列化类可以通过声明字段名来显式声明自己的UID。
它必须是static、final和long类型。例如:
1
| (public/private/protected/default) static final long serialVersionUID=42L;
|
如果可序列化类没有显式声明serialVersionUID,则序列化运行时将根据类的各个方面为该类计算默认值,如Java对象序列化规范中所述。但是,强烈建议所有可序列化类显式声明serialVersionUID值,因为它的计算对类细节高度敏感,这些细节可能因编译器实现而异,因此类中的任何更改或使用不同的id都可能影响序列化的数据。
还建议对UID使用private修饰符,因为它作为继承成员没有用处。
