
Opening
今天开始就正式是2024年的暑假了,各种意义上,都是很关键的一个半月。
自从打算考研以来,我几乎没有一刻为准备考研本身和承担与之对应的风险而难受或者后悔,研究极限或者积分也好,背单词也好,看数据结构的算法题也好,都非常有趣。而且在漫长的人生中,能让你有如此充分的理由,安心研究数学或者计算机基础的机会实际上非常少。虽然超出预料,但决定考研是我正确的选择。
但几个月以来,我还是被自我所囚禁,事到如今仍然对自己充满困惑。考研本身让人只感到有趣,但选择考研意味着大学生活走向尾声,却让人停不下负面思考。三年过去,自己不但没有做到想做的事,甚至连自己究竟想要的是什么都完全没搞明白,实在是很让人沮丧的事实。青春走向尾声,却仍然是迷途猫。
在自己没意识到高中与高考对自己的束缚中,度过了三年中的大部分时间。悟己往之不见,知来者之可追。到已失去选择时,才发现自己的懦弱与愚蠢。拥有世界上最麻烦的性格,实在运气不好:(
言归正传,考研本身是很有趣的过程,所以决定记录下每天的进度作为日志,此记。
7.12
线代
全书和线代讲义的矩阵部分复习
这部分题目考察概念,有点难度。
- 对行向量和列向量的乘积理解很重要,左行乘右列结果是数,左列乘右行结果是n*n矩阵。
- 对角矩阵相乘,结果仍然是对角矩阵,且对角线上的值是两个乘子相应对角线的乘积。
高数
660极限选择题
出乎意料地连错五个选择,除了对极限概念有忘记以外,看了答案仍然没搞懂的还有一个。果然基础是王道啊。
极限概念的关键:函数在某点的极限值,与该点函数值本身没有关系。
连续:直接求左右极限判断即可,无需关心分界点是大于等于还是大于。
无穷大与无界:无穷大要求任意值都任意大,而无界要求存在任意大的值。
因此无穷大可以推出无界,反之不能。
无界的充要条件:存在极限是无穷大的子数列。
660微分选择题
导数定义有两种形式,但分子一定是动点减去静点:f(a + Δx) - f(a)
数据结构
复习栈+做对应选择题,题目比较简单。
计组
计算机基本体系结构
程序由高级语言转换为可执行机器码的流程:
预处理 -> 编译 -> 汇编 -> 链接
注意:编译后的仍然是文本文件,只是翻译成了汇编代码。
辨析:编译与翻译
由高级语言转为低级语言(即汇编)为“翻译”。
由高级语言生成可执行代码(机器代码)为“编译”。
概率论
初步复习抽样分布
7.13
高数
660微分/导数选择题
这部分也是概念题最多,正确率大概60%。
可导的概念
函数在x = a处可导:
- f(x)在a处连续
- x趋近于a时f’(x)的极限存在,即
$$
\lim_{x \to x_0} f(x) = A
$$!!注意:只有第二个条件时,不能推出f’(a) = A存在,即函数不一定连续,也即不一定可导。!!
需要强化的极值点和拐点判断知识点:
当该点可导时,是极值点的必要条件是导数为0,不可导时则没有此限制。
x = a处可导时,极值点判断:必要条件是f’(x) = 0,充分条件有三种:
- 一阶导判断:f’(x)在a左右两侧异号
- 二阶导判断:f’’(x) ≠ 0,
f''(a) > 0时为极小值,反之为极大值 - n阶导判断:求n阶导最后的奇数时是极值点
拐点:左右两侧凹凸性相反的点。拐点判断与极值点完全类似,但是所有导数高一阶,例如可导时,该点的二阶导f’’(a)=0是必要条件。
- 极限运算法则的结论:如果A/B的极限存在,且B为0,则A的极限也是0
这个结论很好用,但要注意“精度”。
在与0比较时,例如比较二阶导是否为0还是大于或者小于0,不能直接看作极限为0,而应该考虑0+与0-。
线代
660矩阵填空题
同样是概念为主的计算题。
有个低级的概念错误:矩阵等价与矩阵相等是两回事,因此计算带等号时,绝不能使用初等变换。
计算矩阵n次方
对秩为1的n*n矩阵,有个计算矩阵n次方的有用结论:
这种矩阵可以化为一个列向量乘一个行向量ab(注意是列向量是左边),此时矩阵n次方可以写成:
A^n = abababab....同时ba的乘积是一个数,因此有:
A^n = L^(n-1)*A,L是矩阵对角线上元素的求和。
数据结构
复习队列并做练习,整体与栈相关题目类似。
计组
计算机性能指标
主要是概念与相关计算:
- 计算机字长:是一次整型计算能最大允许的长度。与ALU和通用寄存器长度相同。
- CPI,MIPS,IPS等概念只要记住对应的英语就很容易:
- C:时钟周期Cycles
- P:每per
- I:指令Instruction
- M:百万Million
- 数量级:十亿是10^9
7.14
想了想,因为打算早点做真题,所以放缓了660高数部分的进度,先推进线代和概率论。
线代
复习全书矩阵部分 + 660矩阵填空题
矩阵是线代的基础,概念和定理很多,整体难度中等:
矩阵乘法相关概念:矩阵的初等变换 等价于 乘一个初等矩阵,其中行变换为左乘对应的矩阵,列变换为右乘对应矩阵。(注意:将某一行乘k加到另一行,就是左乘一个以E为基础的初等矩阵)
乘法与行向量/列向量:可以将矩阵乘分解为行向量乘列向量,对A和C都是由向量线性组合组成的矩阵乘法,如
AB=C,可以用这种分解矩阵的方法很快求出B。矩阵方程求解:使用初等行变换法更高效,对
AX=B直接用(A|B)->(E|X);对XA=B,先两边求转置化为A^T * X^T=B^T的形式再用初等行变换求出X^T,最后再转置得到X。矩阵求逆:这个也是初等行变换,需要注意的只有两点:
- 只能使用初等行变换,不能用列变换
- 有数乘时,一定记住提出来后最后要乘上,否则会出错————还是矩阵等价与相等的问题,初等变换中只有数乘会改变矩阵的大小,但行列式出现交换时要变号。
伴随矩阵:实际上就一个公式最重要:
A*A = |A|E,求逆矩阵那个是两边乘A^-1。- 需要注意的是求伴随矩阵时,将所有的代数余子式写好后,需要加一步“转置”才是伴随矩阵。
- |A*| = |A|^(n-1)也很常用
高数
660微分选择题
做了三道全对,主要是昨天的概念题目
数据结构
栈与队列的应用
比较简单
矩阵与数组
这部分比较像找规律题,不难但需要花功夫,主要需要注意的是矩阵与数组从0还是从1开始,以及上三角矩阵与下三角矩阵计算的不同。
7.15
昨天看了欧洲杯决赛,英格兰尽力了,但这是属于西班牙青春风暴的夏天。

罗德里拿金球吧,从未见过如此赛场统治力的后腰。
线代
复习全书向量组与线性相关部分 + 660向量组填空题
线代第三章是向量组,同样是概念又多又杂的章节,660题目难度一般,全书上的证明题很难。
主要知识点:
向量组的线性表示,线性相关,向量组的秩之间的关系
- a可以由b1,b2,b3有有唯一的线性表示 <=> b1,b2,b3线性无关 <=> 矩阵A=(b1,b2,b3)的秩为3 <=> 矩阵可逆 <=> |A|!=0
- a与向量组(b1,b2,b3)线性相关 ==>
r(a,b1,b2,b3) = r(b1,b2,b3) - a与向量组(b1,b2,b3)线性无关/不能由向量组线性表示(注意:此时也说明b向量组这三个向量必然线性相关,否则应该可以表示所有维数相同的向量) ==>
r(a,b1,b2,b3) = r(b1,b2,b3) + 1 - 向量组A可以由向量组B线性表示时,r(A) < r(B)【其实也很直观,因为B能表示A,则说明B包含有效维度/有效信息更多,因此秩更大】,且B若有n个向量,则最多表示n个线性无关的向量。
求向量组的秩与矩阵的秩有不同:
求向量组时,无论是给出行向量还是列向量,都可以转置为列向量再凑成矩阵,此时对该矩阵做初等行变换即可得到阶梯型矩阵(注意:向量组只能用行变换),非零行即为秩。
求矩阵时可以直接初等变换,而且行变换与列变换可以混用,因为矩阵行向量与列向量线性关系等价。
矩阵/向量组的极大无关组:
化为阶梯型矩阵时,每个阶梯处第一个非零元素对应的列即为一个极大无关组。其中的列向量均为线性无关,且再多加一个向量就变为线性相关。
因此可以用极大无关组中的向量表示其他向量:非极大无关组的列向量对应一个等式,例如第四列(1,0,3)^T说明列向量a_4可以由
a_1 + 3*a_3线性表示。注意:不只有一组极大无关组,例如秩为3时,三个线性无关的列向量就能凑为一个极大无关组。
矩阵与其伴随矩阵的秩的关系:
- r(A) = n ==> r(A*) = n
r(A) = n - 1==> r(A*) = 1 (最常用)- r(A) < n - 1 ==> r(A*) = 0
矩阵求秩时简化运算:矩阵乘另一个
可逆矩阵时,其秩不变。分析概念时,经常需要考虑矩阵为零矩阵和数乘参数为0的情况
高数
660微分选择题
5/6,仍然是概念错误:f(x)与f’(x)的有界性在无穷区间上没有关系,在有界区间上:
f’(x)在(a,b)上有界,f(x)在(a,b)一定有界
f(x)在(a,b)上无界,f’(x)在(a,b)上一定无界(逆否命题)
其实这个结论很直观,因为导数相对于原函数“降阶”了,比函数更可能出现x在分母,在x=0时更可能无界。
数据结构
串的匹配与KMP算法
KMP算法很有难度,但考察难度不大,主要搞明白next数组如何构建和“最大相同前后缀长度”的概念即可。
7.16
高数
660微分/积分选择题
6/7 依然是概念。
原函数存在定理,只要满足以下之一即可:
- 函数连续
- 有限个间断点
- 函数单调
注意:因此可以推出原函数存在的函数不一定连续。
线代
复习全书线性方程组部分 + 660线性方程组填空题
这部分内容相对较少,关键核心是如何求解齐次方程和非齐次方程的通解,具体概念:
非齐次线性方程
AX = B解的判断:未知数个数为n时- r(A) = r(A|B) = n:有唯一解
- r(A) = r(A|B) < n:有无穷多解(其实很直观,即有效方程数小于未知数个数,没有确定解)
- r(A) < r(A|B):无解
注意:有无穷多个解时,其中包含多个线性无关的基础解系,即线性方程组对应向量组的极大无关组。
齐次方程
AX = 0解的判断更单纯:- r(A) = n时只有唯一的零解
- 反之r(A) < n时有解
齐次方程基础解系中解向量的个数s 与 未知数个数n和向量组的秩r有关:
s = n - r(A)- 注意:如果给出的是非齐次方程,可以用非齐次的两个特解相减得到齐次方程的特解,再代回可求得对应齐次方程的基础解系中解的个数。
这部分660题目难度不大,主要是求解非齐次通解的流程要搞明白
!!线性代数最根本的运算是初等变换,求某个向量组或者方程满足某种条件时,通常转化为对应的矩阵A的秩满足某个条件,但有时难以计算,此时如果有
向量组线性相关/矩阵秩<n时,可以用行列式|A| = 0方便计算。!!
计组
定点数表示与存储
这部分难度中等,主要有下面几个部分需要注意:
对用补码表示的负数的反直观性质:数值部分越大,对应的真值越小。
有符号数与无符号数的相互转化:符号位作为数值位,或者数值位作为符号位,注意在第一位是1时,转为符号位对应负数,此时后续的数据“视为负数补码”,因此计算真值时要再取反加一。
强制转换导致数据位数增多时:用原本数的最前面一位补足。
数据结构
树的基础概念
主要是基础概念,注意有个常考数量关系:
- 树的分支数/边数 + 1 = 树的节点数n
- 树的分支数 = 所有结点的度数(例如度为3的树,3 * a_3 + 2 * a_2 + 1 * a_1)
通过上面两个可以建立子式,经常用来求叶子节点(即度为0的节点)数量。
7.17
今天下午下暴雨,晚上摸鱼了,所以专业课今日进度缩减。
高数
660积分选择题
5/8 依然是积分的基本概念,难度不大但正确率一般。
要注意的主要是:
定积分不等式:m <= 定积分 <= M 要注意使用条件:只能在函数始终大于等于0时用
可积的线性性质:不可积函数f(x) + 可积函数g(x) = k(x) 此时k(x)一定不可积。
很容易使用反证法证明:如果k(x)可积,则有k(x) - g(x) = f(x)可积,与条件矛盾,故不可积。
这种反证法的思路对考察连续、可导、可微、可积等概念的线性组合很常用。
不该犯的错误:tan(x)在x趋近于pi/2和-pi/2时,函数值趋近于无穷,即便tan(pi/2)定义为其他固定的点【例如(pi/2,1)】,tan(x)在该区间上仍然是“无界函数”。
比较大小时,对积分区域上有正有负的定积分,可以先拆为正区间积分和负区间积分,再用换元等化为同样的正区间再比较
例如对sin(x)的[0, 2pi]区间,可以转为[0, pi]和[pi, 2pi],再用换元
x = pi+t/t = x - pi,此时第二个负区间上被积分函数就转为了[0, pi]上的-sin(t)。!!注意:对三角相关的函数,
x = pi + t或者x = pi - t的换元很常用.!!
线代
复习全书特征值与特征向量部分 + 660特征值填空题
这部分概念也很多,但整体不太复杂,主要是与前面内容的联系或者对矩阵方程求解的考察。
特征值和特征向量的两种求法:
- 特征值和特征向量的基本定义:
Aα = λα - 列方程求解特征值:
| A - λE | = 0,即求行列式/特征方程组,关键是化简行列式 - 将特征值代入求矩阵方程:
(A - λE)X = 0求解X的极大无关组/基础解系,再线性表示就得的特征向量。
- 列方程求解特征值:
- 特征值和特征向量的基本定义:
特征值与特征向量的性质:
|A| = 所有特征值求乘积
若A的特征值为a,则f(A)的特征值为f(a):例如(A+E)的特征值为a + 1
若A可逆,伴随矩阵A*的特征值为|A|/a,逆矩阵特征值为1/a
若A可逆,则A、A*、A^-1的特征向量相同
如果n阶矩阵的秩
r(A) ≤ 1,此时矩阵的特征值有n-1个0(或矩阵特征值中的0为n-1阶),还有一个矩阵对角线求和(即矩阵的迹)。这个性质可以直接求出矩阵的特征值,可以简化特征值计算。
对秩不是1的矩阵,如果通过线性变换或者加减E转为r=1,也可以用
不同特征值对应的特征向量互相线性相关。
特征值判断矩阵可逆:当0不是矩阵的特征值时,矩阵一定可逆
实对称矩阵:
- 所有元素为实数。对称矩阵条件:
Q^T = Q - 所有不同特征值对应的特征向量彼此正交。
- 所有元素为实数。对称矩阵条件:
操作系统(debut)
计算机系统概述
并发与并行:
- 并发:一段时间内同时执行(通过进程实现)
- 并行:同一时刻同时执行
操作系统的最基本特征:并发与共享
7.18
高数
660积分选择题
5/7,实际上还有歪打正着的题目,整体难度较高
最关键的要点:求定积分时,当被积分函数出现类似sqrt(cos(x)^2)的绝对值【例如|cos(x)|】,一定要注意积分区间内函数正负
尤其对[0,pi]区间上的三角函数绝对值,需要将积分区间拆开求解【好吧,和昨天的注意是类似的】,但尤其对换元后出现|sinx|或者|cosx|时一定要判断正负。
牛顿-莱布尼茨公式的使用条件:函数在区间上连续,且有界
- 注意:无界函数不能求定积分,例如1/x在[-1,1]上定积分就不存在。
线代
复习全书矩阵相似、相似对角化和实对称矩阵部分 + 660矩阵相似填空题
这部分概念也较多,尤其是计算实对称矩阵的计算量非常大,但题型比较固定:
A与B矩阵相似的条件:
- 存在可逆矩阵P,有
PAP^-1 = B,此时A与B相似 - 上面条件的变形:
PA = BP - A与B的特征值相同,且均可对角化
- 存在可逆矩阵P,有
相似的性质:
|A| = |B|
r(A) = r(B)
特征值相同
f(A)与f(B)也相似
特征向量的关系:
β = P^-1 * α注意:相似时有很多性质,但不能直接代入矩阵方程求解
相似对角化:当矩阵与对角矩阵相似时,称为可“相似对角化”,此时特征值很容易求出
可对角化的条件:
- 特征向量:所有特征向量线性无关
- 特征值:
- 若矩阵的特征值各不相同(实际上等价于特征向量都线性无关), 则矩阵一定可以对角化
- 若矩阵存在特征值λ的重数大于1,则需要重数
k = n - r(A-λE)
实对称矩阵:
元素均为实数
实对称矩阵均可以“对角化”
不同特征值对应的特征向量均正交(因此如果三阶矩阵特征值均不相同,知道两个特征向量,可以用向量正交求出第三个【有一个自由变量很正常,如果不理解可以翻看前面线性方程组基础解系的部分】)
实对称矩阵的正交化:即给出矩阵A,求正交矩阵P,使A与P^-1*A*P为对角矩阵
- 先求A的特征值,再代入|A-λE|得到特征向量
- 当有多于一重的特征值时,对同一特征值的特征向量使用施密特正交化,一般只需要用
b2 = a2 - (a1*a2)/(a1*a1) * a1 - 对得到的正交向量单位化,合并在一起就得到对应的正交矩阵。
这部分660的题目都比较简单(虽然正确率只能说一般。。。),再次复习时要多做几遍全书的题目,很有技巧。
数据结构
二叉树与树的遍历
整体难度不大,仔细算就不会出错。
- n个节点的二叉树用双链表存储时,有n-1个空域指针
- n个节点的二叉树用三指针链表(多了一个指向父节点)存储时,有n个空域指针
- n个节点的三叉树用三指针链表存储时,有2n-1个空域指针
树的递归遍历很直观,非递归实现则比较复杂。
7.19
高数
660积分选择题
5/8,正确率不高,但整体难度还好。
需要注意的是:选择题能计算时最好直接计算试一下,不能凭直觉猜。
- 如果f(x)是以T为周期的周期函数,则f(x) - f(-x)也是。
线代
复习全书二次型部分 + 660矩阵二次型填空题
这是线代的最后一部分,综合性很强,但考察难度不高。
f(x) = x1^2 + x2^2 + 3x1x2…这种形式的多项式函数称为“二次型”,可以写成实对称矩阵:
X^T*A*T。注意对x1x2这种项,对应矩阵的元素是系数的1/2(因为对应两个项:x1x2和x2x1)标准二次型:只有平方项的二次型,任何二次型都可以化为标准二次型(因为实对称矩阵一定可对角化)。即对二次型对应的实对称矩阵做对角化(对应对角矩阵的特征值就是二次型平方项的系数),称为标准化。
- 标准化的两种方法:
- 正交变换法:先求特征值,再代入(A-λE)X=0求特征向量,做正交化,再凑为正交矩阵即可,对应的标准型的平方项系数就是几个特征值。
- 配方法:配(x1+x2+x3)^2再加减对应项凑标准型
- 标准化的两种方法:
规范二次型:即标准二次型 + 平方项化为±1(即在正交变换法上又多了对特征向量的单位化)
惯性定理:二次型的标准型可以有多种,但化为标准型后,正项和负项的个数都是固定的。其中正项称为正惯性系数,负项则为负惯性系数。
合同矩阵:对n阶矩阵A和B,若存在可逆矩阵C,使
B = C^T*A*C,此时A与B为合同矩阵。合同性的判断:两个矩阵惯性系数相同(即标准型的系数/特征值正项和负项个数相同)时合同。
相似与合同:相似时矩阵特征值都相同,但合同只要求正负项个数相同,因此相似矩阵一定合同
正定型:若有二次型对任何向量X都有f(x)>0,此时称为“正定二次型”,对应矩阵为正定矩阵。
正定矩阵的判断:
特征值:矩阵的特征值均大于0
正惯性系数:个数为阶数,即p=n
可逆矩阵:存在可逆矩阵P,使
A = P^T*P主子式:即矩阵对应的n个主“子行列式”均为0,例如三阶矩阵,则有1、2*2和3*3(即矩阵行列式本身)均为0。(最常用,计算时行列式最方便,应该多用)
明天开始看全书的概率论部分了,今天看了贝叶斯和全概率公式,难度还好。
数据结构
二叉树的遍历与线索二叉树
这是今天最难的部分。
前序遍历/中序遍历/后序遍历/层次遍历的概念都很清楚,递归实现也很直观:
1 | typedef struct TreeNode |
但具体分析起来却有点复杂,尤其是判断通用结论时不太直观,要特别注意。
7.20
今天是回归天空之日~~~
今天开始做660的概率论,线代先放一下。
数据结构
树的遍历与森林/树的二叉化
难度较大,但认真做就不会错,所以正确率很不错。
要注意的概念:
- 后序线索二叉树的后继遍历:只有这个线索二叉树遍历是不能仅靠线索指针就能实现的,而是需要用栈
- 森林/树与二叉树的转换:转换前的叶子节点数 == 转换后没有左孩子/左指针域为空的节点数
- 计算节点数时,如果直接推导比较困难可以用特殊值
- 给出为某种普遍的条件的时,要考虑对应的各种情况:例如u节点是v节点的父节点的父节点,此时u和v的关系有四种情况:即固定u,则u的孩子有左右两种,对应孩子的孩子又有左右两种,需要每种都考虑。
高数
660反常积分选择题
2/3 这部分也有点难度,而且与级数有点相关。
可积与原函数存在没有关系:
- 可积只需要满足有界+有限个间断点即可,但原函数存在需要函数“连续”
- 或者说存在第一类间断点的函数一定不存在原函数(反过来说求出的原函数在该点处不可导)
反常识:R趋近于正无穷时,在[-R,R]区间上对sin(x)的定积分为0;但[-∞,+∞]区间上对sin(x)的定积分不存在(因为没有固定值,是发散的)。
- 因此对实数区间上的奇函数f(x),其在负无穷到正无穷的定积分可能不为0(函数也可能发散)
对给定区间上的反常积分,可以分区间讨论大小放缩,另外当[1,∞]上发散时,[0,∞]也一定发散。
发散 + 发散 = 一定发散(级数时则不同:发散 + 发散 = 不一定)
收敛 + 发散 = 发散
几个常见错误:

概率论
全书概率论第一章 + 660填空题
7/9,整体比较简单,需要注意的不多:
事件运算其实有点复杂,最好画个文氏图看看更直观。
事件独立时才有P(AB) = P(A)P(B),否则不能计算
根据给出的条件灵活用德摩根律转化和事件与积事件
7.21
高数
660定积分应用
6/6 难得全对,这部分只要记住公式就好办
- 计算极坐标弧长:
ds = sqrt(r'^2 + r^2)da - 平面曲线计算质心:(X,Y)
- 给出为参数方程x(t),y(t)形式:
- X = 求定积分[x(t) * sqrt(x’^2 + y’^2)]dt / 定积分sqrt(x’^2 + y’^2)dt
- Y = 求定积分[y(t) * sqrt(x’^2 + y’^2)]dt / 定积分sqrt(x’^2 + y’^2)dt
概率论
全书概率论第二章 + 660填空题
不难,记住几个分布、概率密度和分布函数的定义即可。
注意指数分布是分段的:
- x > 0: λe^-λx
- x < 0: 0
因此计算分布函数时直接从0开始算定积分即可。
数据结构
哈夫曼树与并查集
这部分难度不大,只是比较麻烦。
构造哈夫曼树时,要比较新生成的根节点与原本节点的大小,如果有两个更小的原节点,则不会加到根节点。
哈夫曼树平均权值的概念:WPL/权值求和
哈夫曼编码与定长编码:
- 编码数均为叶节点数
- 定长编码对应的二叉树:所有节点均在同一层,即层数 = 定长编码长度
计组
定点数运算
这部分有难度,尤其要注意各个标志位的概念。
OF:0标志位,运算结果为0时置1,反之置0;
两个溢出标准位:CF是无符号数溢出标志,OF是有符号数溢出标志。
CF:进位/借位标志位,只对无符号数有意义
- 当相加时最高位出现进位,或结果超过该字长表示的范围;
- 相减不够减时置1;
OF:溢出标志位,只对有符号数有意义,当溢出时置1:
- 溢出判断:
- 最高位(符号位)进位与次高位(即数值位最高位)进位不同,即最高位进位/次高位不进位 或 最高位不进位/次高位进位 时溢出;
- 正数相加结果位负 / 负数相加结果位正,溢出
- 直接转为十进制判断是否在该字长能表示的范围内:[2^n-1, 2^(n-1)-1],例如8位时[-128, 127]
- 溢出判断:
SF:符号标志位,只对有符号数有意义,结果负数时为1,正数时为0.
特别注意:这里的有符号数和无符号数,实际上是人为解释的,计算机中只有补码的机器数,因此只给出数字和运算,判断CF和OF时,应该做两种判断:即有符号数和无符号数。
ALU加减运算
这部分要看下对应的数字电路结构。
ALU对加减运算,原码加减与补码加减、或者说有符号加减和无符号加减是一样处理的。
ALU有三个输入:两个加法因子X和Y,一个Sub控制命令
Sub:
- 0:加法运算
- 1:减法运算
但加法器得到的输入并不是直接输入的加法因子,而是经过控制命令Sub判断处理的。
即输入ALU后,Y会取反为Y^-1,此时有几种情况:
- sub = 1:X + Y
- sub = 0:X + Y^-1 + 1
注意减法的加一很容易忘记。
负数的补码表示
与之前一样,这次仍然忘记了一个关键问题:
!!!遇到FF开头,即1开头的机器码,先取反加一转为对应的真值再加负号。!!!
直接把负数补码的数值位当作真值,是很容易犯的错误!
7.22
高数
660微分方程选择题
7/9 这部分比较难,但正确率还好
已知齐次方程的两个不同特解y1,y2,则通解为:C*(y1-y2)
- 因为可能出现零解,但y1-y2一定不是
求高阶非齐次方程特解的叠加原理:
- 当所求方程的右半部f(x),是由三角函数,e^x和多项式的“和”形式构成时,可以把每个加项拆开单独计算设非齐次方程特解
- 之后再把每个特解求和,即得到原方程的特解
概率论
全书概率论第三章 + 660多元随机变量的分布填空题
这部分终于难起来了,要仔细思考才行。
正态分布的分布函数可以转化为标准正态的分布函数:
F(x) = Φ[(x-u)/σ]标准正态分布的分布函数:
Φ(-x) = 1 - Φ(x)Φ(0) = 1/2
求联合概率密度时,一定要注意定义域范围。
对离散型和连续型的组合随机变量,常用全概率公式求联合概率密度:
- 即f(x,y) = f(Y|X=0)*P{X=0} + f(Y|X=1)*P{X=1} …
数据结构
图的概念
这部分出乎意料的很有难度,对基本概念的考察很有深度。
连通图:每个节点都能到其他任意一个节点(注意:不要求直达)
- 每个节点都能直接连接其他所有节点时:为无向完全图,此时边数为n*(n-1)/2,有向时乘二。
给出节点数,求最少需要几条边,一定得到连通图时:
- 构造n-1个节点的完全图,如何再加一条边连接第n个节点。
- 此时边数任意分配,总能实现连通图。
连通分量:极大连通子图
注意:
- 这里是极大,即最多容纳节点,且是连通图的子图
- !!!对有向图,只有入度没有出度、或者只有出度没有入度的节点,自身是一个强连通分量!!!
给出边数与节点数,求最大连通分量个数:
- 最大连通分量数,即最大独立节点数时,此时需要用尽可能少的节点数用完所有边
- ==> 所有边组成一个完全图
7.23
高数
660微分方程选择题
难度还好,题目比较常规
计算出特解的形式时,如果给出的是具体的微分方程,或者参数限定了“范围”,需要再将特解形式代入
判断是否会有不同形式,例如可能由Axsinx+Bxcosx变成Bxcos(x)
归根结底,求特解时还是代回去验证效率最高,而且不容易出错。
伯努利方程:非齐次的自由项包含y^n,此时设z=y^(1-n),求z’和y’
欧拉方程:y’’x^2 + y’x + y …,设e^t=x,求y’’和y’代入
概率论
全书概率论第三章 + 660二元随机变量的分布填空题
今天结束二维随机变量,整体难度不高:
正态分布的线性组合,仍然是正态分布,且具体参数为
aX+bY ~ N(au1 + bu2, a^2 * σ1^2 + b^2 * σ2^2 + a*b*σ1*σ2*ρ)- ρ为两个变量的相关系数,独立/不相关时为0
二维连续型随机变量的概率密度:卷积方程
- Z=X+Y:f_Z(x) = 在[-∞, +∞]对f(x,z-x)求x的积分
- 独立时:f_Z(x) = 在[-∞, +∞]对f_X(x)*f_Y(z-x)求x的积分
对连续型与离散型的组合求分布函数:
- 直接写成P{X<=x}再推导
- 多用全概率公式直接简化离散型
数据结构
图的存储
难度一般,主要是为后面的遍历做基础:
- 四种存储方式:
- 邻接矩阵
- 邻接表
- 十字链表(只用于有向图)
- 邻接多表(用于解决邻接表存储无向图浪费一倍空间,因此只用于无向图)
7.24
高数
660多元微分选择题
本以为自己对这部分概念有理解,结果还是太嫩了,错了一半还多:
多元函数极限:
- 设y=kx或者y=x^2,代入判断是否为定值,有定值则极限可能存在,反之则一定不存在
- 注意:如果代入一个发现存在,仍然不一定极限存在,可能与其他值不同
多元函数连续性与偏导数存在没有关系
- 一元函数可导必连续,连续不一定可导
多元函数用定义求偏导:
例如点(x_0,y_0)处对x的偏导数:
$$
\lim_{ h\to 0} \frac{f(h,y_0) - f(x_0,y_0)}{h}
$$注意:这个式子中分子第一项是(x_0,y_0)以外f(x,y)表达式,可以将y_0直接代入,第二项是具体值
判断偏导数连续性:
偏导数存在时,判断可微需要看偏导数在某点是否连续:
$$
\lim_{(x,y)\to (x_0,y_0)} f_x’(x,y) = \lim_{(x,y)\to (x_0,y_0)} f’_x(x,y_0) = f’_x(x_0,y_0)
$$先代后求:对定点求x的偏导时,可以直接将y_0的值代入f(x,y),再求x的导数会方便很多
注意:有个反直观而且容易忽略的地方:
$$
\lim_{x\to x_0} f’_x(x,y_0) = f’_x(x_0,y_0)
$$上面这个式子不能等价于偏导数在(x_0,y_0)处连续,是必要条件不是充分条件。
多元函数可微性判断:
必要条件:偏导数都存在
充分条件:偏导数连续
注意:偏导数连续一定可微,但可微不一定有偏导连续/偏导不连续不一定不可微
定义/公式法判断可微性:
$$
\lim_{(x,y)\to (x_0,y_0)} \frac{f(x,y) - f(x_0,y_0) - [f_x’(x_0,y_0) + f_y’(x_0,y_0)]}{\sqrt{x^2+y^2}} = 0
$$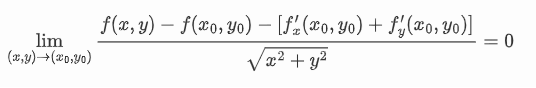
数据结构
图的遍历 & 图的应用
BFS与DFS,整体考察难度一般
需要注意存储为邻接矩阵和邻接表的BFS/DFS时间复杂度不同。
概率论
全书概率论第四章 + 660随机变量的数字特征填空题
这部分也不简单,而且与前面的各种分布结合密切。
- 相互独立的随机变量,其函数也都独立
- 尤其是X和Y独立,则X^2和Y^2独立,对计算E(X^2*Y^2)很重要
- E(X+Y)^2和[E(X+Y)]^2写法不同,要注意
7.25
这两天一直在纠结到底考哪里,效率不高。
信工所不错,而且比较好考,但不是985有点不甘心。
东南网安或者川大电科又更难
高数
660多元微分选择题
考察偏微分几何意义,这部分掌握不错,难得全对。
- 偏微分存在 => 对应的一元函数f_x’(x,y_0)一定连续,但二元函数不一定连续
- 偏微分的几何意义:
- 对x和y方向上的趋势:f_x’>0则为增加,反之为递减
数据结构
图的应用
这部分内容巨多,但搞明白就不容易错,正确率很高.
- 主要的两种算法:
- 找图的最小生成树(注意:与最短路径没有必然关系)
- Prim
- kuruskl
- 寻找最短路径
- 单源最短:dijstra
- 整体最短:flord
- 找图的最小生成树(注意:与最短路径没有必然关系)
概率论
全书概率论第四章 + 660随机变量的数字特征填空题
依然是难度不小:
- 关键是对各个分布的概率密度和分布函数完全记住:
- 计算期望或者方差时,不要直接硬算,最好先比较下与已知的分布
- 可能提取出常数就能化为已知分布(尤其是指数分布和正态分布)的函数
- 期望与方差的不同:
- 变量相互独立时:D(X+Y) = D(X) + D(Y) / E(XY) = E(X)E(Y)
- 不独立也可以:E(X+Y) = E(X) + E(Y)
7.26
依然纠结中……
今天效率很低,而且没有专业课进度
高数
660多元微分选择题
不算难,仍然是基础概念:
计算偏微分时一定要注意给出函数的区间:
例如f(x,y)在xy=0时为1,其他为0,此时二元函数在(0,0)处极限不存在
因为只有从x=0或y=0趋近于原点时,函数极限为1,但其他方式趋近于(例如y=kx)时函数值为0
二阶混合偏微分相等(f_xy’’==f_yx’’)的条件:
- 对x和y的偏微分均存在且连续
- 用定义求时最好分开求,并且用先代后求:
- 例如求(0,0)处的混合二阶偏微分先求f_x’(x,0),求出关于x和y的函数g(x,y)【注意:求完一阶偏导之后仍然是关于x和y的二元函数】
- 再对g(x,y)求y的偏导g_y’(0,y),此时得到二阶混合偏导在(0,0)的值
这部分题目别想太多,先算,多写几个式子可能就搞明白了。
概率论
全书概率论第四章 + 660随机变量的数字特征填空题
这部分内容很多,题目也不简答,因此多做了点全书的题目。
- 注意:对独立同分布累加型的随机变量,最好将其化为一边固定对应另一个累加
7.27
决定了,就考西工大网安了。
考计组+计网,而且大部分是硬件相关的研究方向,感觉不赖。
高数
660多元微分选择题
认真做下来又全对了,还是基础为王啊。
定积分性质:
- 对f(x,t)求dt的定积分,再对x求偏导 = 对f(x,t)求x偏导,再对dt做定积分
- 实际上就是原函数求导得函数,和导函数求积分得原函数次序可以交换
多元微分计算混合偏导时,要记住f_x’仍然是二元函数
二元函数极值只可能在三种:
f_x’=f_y’=0的驻点
偏导数不存在
条件极值时:边界
求条件极值边界上极值的两个方法:
求出y=g(x),再代入f(x,y)求一元极值(最好用)
设L(x,y) = f(x,y) + λg(x,y)
- L_x’ = 0
- L_y’ = 0
- L = 0
即拉格朗日数乘法,比较麻烦。
概率论
依旧做全书题目,还是要对随机变量函数的分布搞明白。
计网(debut)
第一章计算机网络体系结构
不难,但概念要搞明白:
速率:即传输数据的数量比时间,注意:单位是bit per second,即比特每秒,而不是字节每秒
时间延迟:发送时延 + 传播时延 + 存储转发/处理时延 + 排队时延
发送时延:或传输时延,即网卡发送速率导致的时间延迟:从第一个比特开始,到分组最后一个比特进入链路的时间。
计算:分组长度/发送速率
注意:计算发送时延时要注意分组一般是以字节B为单位,而速率是以比特b为单位,最后结果要乘8
传播时延:即数据在链路上传播所需的时间,一个比特从链路一端开始计时,到达链路终点时的时间。
- 计算:信道长度/电磁波在该链路上的传输速率
为什么没有接收时延:因为发送时延与传播时延已经包含了完整流程里的接收部分。
7.28
今天是成都少女偶像only,而且我还在成都邦邦群抽到了门票。
所以摸鱼了。
还蛮有趣的,同人也好 live也好
7.29
高数
660多重积分选择题
不难
- 关键是对计算要有自信,发现复杂计算时不慌,相信能求出来
概率论
全书概率论第五章 + 660大数定理填空题
整体难度不大,主要还是考察前面的知识:
- 切比雪夫不等式:
P{|X - E(X)| >= e} <= D(X)/e^2- 注意大于号、小于号与绝对值,以及该不等式只能求X+u与X-u范围内
- 大数定理使用的要求:
- 存在分布函数
- 存在期望和方差
- 辛锌大数定理:
- 对独立同分布的n个随机变量序列,当n趋近于无穷时,X_n的算术平均值依概率收敛于X_i的数学期望。
- 中心极限定理:
- X_n是独立的随机变量序列,期望于与方差都存在,X_n序列极限分布为正态分布
- X_n ~ N(n*E(X), n*D(X))
- 拉普拉斯定理:
- 正态分布是二项分布的极限分布,当n足够大时,可以用正态分布近似计算二项分布。
- X_n ~ N(np, np(1-p))
计网
物理层
这部分简直是通信原理,主要是两个公式:
奈氏准则:不考虑噪声,信道的不被码间误差模糊数据的最大传输速率:
$$
2Wlog_2{V}
$$W为信道带宽/传输速率,V为一个码元包含的信息量/不同单元数(例如4bit为16种不同单元)
香农公式:考虑噪声的信道最大传输速率:
$$
W*log_2{(1+S/N)}
$$S/N为信噪比,有两种写法:
- 信号功率/噪声功率的比值
- dB分贝,例如30分贝,则比值写法为10^3
7.30
今天和室友吃烤肉去了,很爽嘛
高数
660多重积分选择题
整体难度不大,这部分其实就是几个主要考点:
- 对称性与奇偶性
- 变量轮转对称性(积分区域关于y=x对称)
- 极坐标与直角坐标系转换
- 极坐标原点平移/换元再取极坐标
要注意的是比大小的题目:
先看区间范围,再比较被积函数的值大小。
计网
物理层
结束物理层,最难的其实就是第一章的通信原理基础。
408对时延的考察相当有深度,需要特别注意的是分组存储转发的核心特点:
每一个分组发送后,其之前的分组仍然在继续向前
因此整体时延考虑只需要看整体发送/传输时延 + (最后一个分组的传播时延 + 转发时延)
概率论
全书概率论第六章 + 660数理统计与样本分布填空题
今天终于进了数理统计之门,之前看了课本仍然一直在门外。
统计与概率是相关但不同的两个概念:
- 概率是指某种理想分布唯一指定的数据
- 但统计是实际存在的数据,受各种因素影响有误差
统计的核心概念:总体与样本,总体是理想分布/概率,样本是随机抽取的某种有误差的数据集。
简单随机抽样取得的样本:独立同分布
统计的基本概念
统计中没有数学期望的概念,对应的是样本的均值,方差则一样有。
样本中的随机变量称为统计量,均值X帽为所有统计量的观察值求和再除以总数n。、
这个很直观,但样本的方差则完全不同。
样本方差
实际上是无偏方差:
$$
S^2 = \frac{1}{n-1}\sum_{i=1}^{n}{(X_i - X^-)^2}
$$
注意与随机变量的方差有两个基本差异:
- 数学期望u变成了样本均值X-,这个很直观
- 1/n变成了1/(n-1),这是怎么回事呢?
- 实际上是因为样本的方差估算有误差,需要用n-1修正
- 或者说是n个数据的样本方差实际上只包含n-1个自由度
- 关于自由度的详细分析参见这篇博客。
样本方差与样本均值三个基本性质
- E(X-) = u
- D(X-) = σ^2 / n
- E(S^2) = σ^2
很容易根据定义推导。
关键要注意总体期望u与样本均值X-,以及总体方差σ^2与样本方差S^2的区别。
7.31
七月的最后一天~七月之if
高数
终于做完了660的1阶高数所有题目,差不多花了一个月。
题目总体不难,越做越顺,有空再把错题刷一遍,今天唯一错的一道:
- 对二重积分,可以把内层函数用g(x)表示,然后分部求
- 这种分部积分有什么用呢?
- 如果内层函数是变上限积分/或者导数很容易求的函数,用分部能化出dg(x)
之后再做2阶,级数和三重积分/线面积分大部分都忘了
计网
链路层
链路层概述 + 组帧 + 差错校验
整体难度不大,要注意的只有CRC和海明校验码:
- 注意“码距”的概念:即某种编码中,两个编码之间最少不同的bit数。
- 纠错n bit:码距为2n + 1
- 校验n bit:码距为n + 1
流量控制
这部分的滑动窗口算法是重点。
话说我记得之前学是在传输层才用的,对了有个区别:
- OSI模型中链路层要保证传输可靠
- TCP/IP中传输层保证可靠
对滑动窗口算法的模拟关键也是对流水线的理解。
另外RTT的两倍的单向传播时延。
计组
浮点数存储与运算
主要是IEEE743规范的内容,很有难度,尤其与前面原码/补码/移码很相关。
注意1开头的机器码,对原码/补码/浮点数均为负数,原码是符号位
浮点数存储有三部分组成:1位符号位 + 8位阶码 + 23位尾数
- 阶码规定数据表示范围
- 尾数规定数据精度
反直觉:int转为float可能有精度损失,因为长度均为32位,但float表示范围大很多,因此精度更低。
浮点数各部分数据:
阶码由移码表示:即真值 + 127(注意不是128,不能直接删去最高位的1)
尾数由原码表示:因为符号位固定了
注意:为多存储一位尾数(提高精度),浮点数要做“规格化”,即化为1.XXXX而不是0.XXXX的形式
有符号位时是把0/1.0XXXXX化为0/1.1XXXXXX
为此需要做左移/右移(或者说左归右归)
注意:左移右移的概念与定点数一样,是数移动几位,而小数点不动