
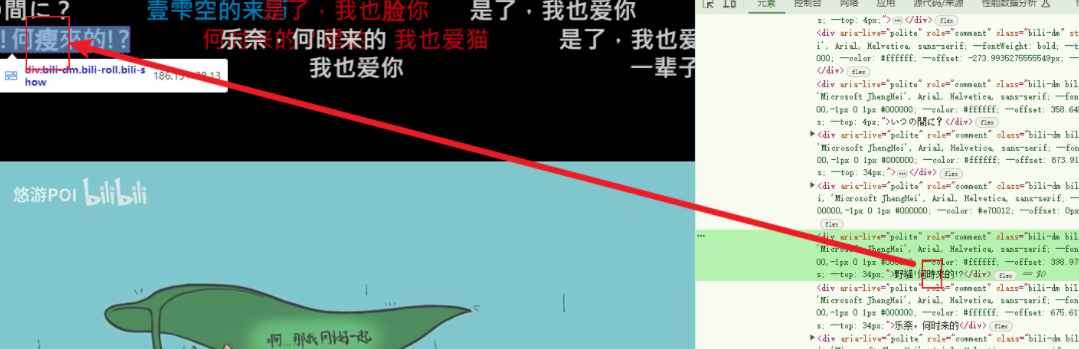
Bilibili网页端视频弹幕Bug
在弹幕为繁体字时,会对其中某些字做转换:
环境:Windows10 + Chrome
其他测试:
- Win10下Edge与Chrome测试相同,Firefox没有出现。
- Linux下没有出现
- Win11下测试Chrome和Edge均未出现
发现的转换:
- “愛”和”脸”
1 | E6 84 9B => E8 84 B8 |
- “時”和”瘦”
1 | E6 99 82 => E7 98 82 |
- “團”和”酥”
1 | E5 9C 98 => E9 85 A5 |
UTF-8与Unicode
当我们谈论字符编码时,我们通常需要区分两个概念:Unicode 编码和字符在计算机内存中的实际表示方式。
Unicode 编码:Unicode 是一个字符集,它为世界上几乎所有的字符都分配了唯一的标识号,称为 Unicode 码点。这些码点通常用 U+XXXX 的形式表示,其中 XXXX 是一个十六进制数。比如,U+7231 表示「愛」这个字符在 Unicode 中的编码。
UTF-8 编码:UTF-8 是一种针对 Unicode 的可变长度字符编码。它将 Unicode 中的字符编码为一到四个字节的序列,以便在计算机中进行存储和传输。对于常见的拉丁字母和 ASCII 字符,UTF-8 使用一个字节表示,而对于其他字符(如汉字和表情符号),则使用两个或更多字节。每个字符在 UTF-8 编码中都有其唯一的字节序列。
现在让我们来详细说明「愛」这个字符的情况:
Unicode 编码:「愛」的 Unicode 编码是 U+7231。
UTF-8 编码:在 UTF-8 编码中,「愛」的编码是 E6849B。这个编码对应着三个字节,分别是 E6、84 和 9B。
因此,「愛」这个字符的 Unicode 编码是 U+7231,而它的 UTF-8 编码是 E6849B。这两者是相关的,因为它们都描述了同一个字符,但是它们所表示的是字符在不同编码方案下的具体形式。
UTF-8计算方式
要从 Unicode 码点计算 UTF-8 编码,可以遵循以下步骤:
确定 Unicode 码点的范围:Unicode 码点是一个十六进制数字,通常以 U+XXXX 的格式表示,其中 XXXX 是一个四位的十六进制数。
确定编码长度:根据 Unicode 码点的范围,确定 UTF-8 编码所需的字节数。UTF-8 编码采用了变长编码方案,不同范围的字符需要不同长度的编码。
确定编码格式:根据编码长度确定每个字节的格式,以及每个字节中哪些位用于表示字符的信息。
转换为二进制:将 Unicode 码点转换为二进制表示。
填充字节:根据编码长度和格式,将二进制表示填充到相应的字节中。
确定首字节的位数:根据编码长度确定首字节的位数,通常是指明后续字节的数量。
填充后续字节:根据首字节的位数,将剩余的字符信息填充到后续字节中。
得到 UTF-8 编码:将填充后的字节转换为十六进制,即得到 UTF-8 编码。
以下是一个更具体的示例:
假设我们要计算字符「脸」的 UTF-8 编码:
「脸」的 Unicode 码点是 U+8138。
根据 Unicode 码点范围,「脸」属于三字节编码的范围。
UTF-8 的三字节编码格式为 1110xxxx 10xxxxxx 10xxxxxx。
将 U+8138 转换为二进制:1000000100111000。
根据 UTF-8 编码格式,填充二进制到对应的字节中:1110 1000 10 100011 10 101000。
首字节有三个 1,表示后续还有两个字节。
填充后续字节:将剩余的二进制信息分配到后续字节中。
得到 UTF-8 编码为 E8 84 B8。
这样,我们就得到了字符「脸」的 UTF-8 编码。